面向能源互联网的数据一致性框架
近年来,以可再生能源、分布式发电等为代表的新能源技术和以云计算、大数据、移动互联网等为代表的信息技术迅猛发展,推动了以能源互联网为核心的第三次工业革命在世界范围内的起步。
作为新能源技术与互联网技术深度融合的产物,能源互联网将可通过分布式智能能量管理系统对分布式能源设备进行广域协调控制,最终实现成为多能互补、用能高效的能源系统。
由于可再生能源与互联网均具有分布式、广域覆盖等共性特征,能源互联网可以借鉴互联网的理念、方法与技术进行建设。从实现方式上,能源互联网的建设必将以新能源技术与面向互联网的信息支撑技术的深度融合为主要手段,这主要包括物理和信息两个层面上的内容:在物理层面上,它要求构建能源互联网物理架构的能源信息一体化基础设施,结合信息网络架构的相关理念,为信息领域先进计算机技术在新能源领域充分、高效的运用提供基础环境,其实例就是能源路由器的提出与实现;在信息层面上,需要通过对分布式能源数据的同步、一致性处理,为面向能源流的智能决策和优化调度提供协调支撑。由于能源、信息及其基础设施的广域分布特征,结合大规模部署的云存储、计算平台进行能源信息数据的存储与处理,为其顶层可再生能源的生产、传输与消纳提供了有效的信息支撑手段,这也是当前世界各国构建能源互联网原型、实现能源信息融合所采取的共有方式。
大规模部署的云架构尽管能够高效地整合物理资源,为新能源管控提供强大的信息数据处理能力,但是为了进行分布式能量的智能管理和能源设备的协调控制,进而支撑可再生能源综合管理、优化存储、统一调度,面向能源信息融合的云架构必须在大规模范围内支持能源数据的广域共享与协同处理。为了实现这一目标,要求云架构能够对数据位于不同云端节点服务器的多份副本进行一致的复制和高效的同步,这在广域环境下是一个极具挑战性的问题:虽然数据副本的复制与同步可以通过传统的复制状态机来实现,但在广域环境下却很难在为所复制的数据提供强一致性的同时保证其高效的性能,原因是广域链路的带宽和延迟是妨碍这两个指标同时达到的瓶颈,已有的解决方案往往都在这两者之间进行权衡。
本文以能源互联网的信息物理架构为基础,探讨如何设计适应于这一架构的数据一致性框架,使其在保证能源信息副本一致性的同时提供高性能的表现,从而有效支撑未来能源互联网顶层分布式能源、信息的共享与协调。
1、能源互联网中的数据同步与一致性
1.1 能源互联网信息物理架构
能源互联网借鉴互联网理念自底向上构建能源基础设施,通过微电网等类似能量自治单元的开放对等互联和信息能量融合分享,增加分布式可再生能源的灵活接入和就地消纳。从物理结构上,微电网、分布式能量等能量自治单元作为能源互联网的基本组成元素,通过新能源发电、微能源的采集、汇聚与分享以及微电网内的储能或用电消纳形成能源互联网中的“局域网”;在此基础上,能源互联网作为分布式能源的接入形式,通过开放对等的信息能源一体化架构来连接任意规模分布式能源,并完成能源(电能)的双向按需传输和动态平和使用“广域网”。大电网凭借在传输效率等方面无法比拟的优势仍是能源互联网中的“主干网”。
图1描述了一个基于能源路由器构建的能源互联网典型场景,其能源物理架构实现了对信息与能源基础设施的一体化融合。该场景包含了一个大电网和三个微电网。作为“局域网”的微电网是能源互联网中的基本单元,其供电由分布式能源和大电网共同支撑。能量路由器是连接各微电网“局域网”之间、“局域网”与“广域网”之间的核心部件,提供了能源质量监控调配、信息数据通信共享、资源维护管理等功能。
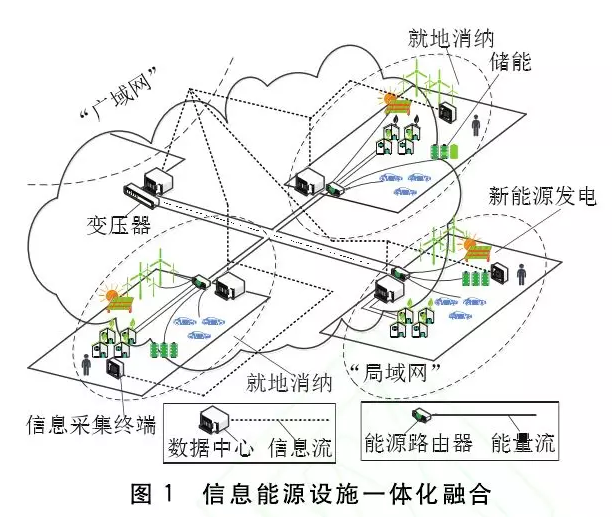
建立各组成单元间能源传输、信息交互的高效通道,是未来能源互联网实现能源供给和消费均衡的需求。灵活而健壮的网络拓扑结构能够在可扩展性、安全性等方面拥有突出优势,其优化配置与部署是支撑能源互联网优化运行的基础。图1中的能源物理架构采用了层次化(树形)的结构。
这种结构具有的优势是:
一方面,当前已有的骨干大电网可作为未来能源互联网骨干线路的选择,能源与信息耦合的配送网络还可为构建能源互联网提供便利;
另一方面,分区域建设的配变设施天然地适应该结构的需求,方便了能源互联网的构建。
1.2 基于多数据中心的云端数据同步与一致性
在信息与能源基础设施一体化过程中,为实现能源互联网灵活的数据采集、存储和分析,支持设备监测运维、电能市场交易、互动服务、需求响应等多种高级应用,采用具备虚拟化、高可用、按需分配、弹性可扩展的云架构是极具有效性、高效能的选择。在信息层面上,云端架构以能源路由器为主要渠道,将获取的能源设施、用户用电、环境信息和系统运行状态等大数据进行存储和计算,从而支撑顶层云端应用系统的高效数据分析与价值挖掘,为供电、调度、用电提供决策支持。
从图1可知,融合了能源和信息基础设施的信息能源一体化架构在能源信息的存储与处理上依赖于云架构的支持,而支持用户、设备、系统随时随地接入和分布式调度的云端架构实际上是以数据中心为核心,并通过信息网络实现互联和交互。云架构针对每个微电网形成的能源“局域网”都部署了一个独立的数据中心。每个数据中心内部通过局域信息网络将其数量众多的服务器连接在一起,而多个数据中心之间则通过连接到骨干网的广域链路进行交互,相互协同、共享,为云应用提供强大的计算和存储能力。
为了支持大规模范围内分布式能源数据的广域共享与协同处理,需要云架构能够将分布于不同数据中心的节点服务器上的多份副本进行一致的复制和高效的同步。在传统的异步、分布式、局域环境下,副本间的复制与同步可以通过复制状态机来实现。复制状态机的目标是使一组可能发生故障的分布式副本以相同的顺序执行相同的请求。只要所有副本都从相同的初始状态开始,并且被复制的服务是确定性的,则所有非故障副本将可以通过执行相同的状态序列来保证分布式副本间的状态同步。从这一角度而言,多份副本间的复制与同步实际上是通过它们对序列每个位置上相应请求的一致性协商来实现的,副本数据所对应的这种一致性具有明确的技术规范。
paxox是用于实现复制状态机的、最流行的一致性协议,它用n≥2f+1(n为副本数
)来容忍f个潜在的副本故障。通过在请求序列的每个位置上运行一个paxos实例,非故障副本将最终在该位置上得到协商一致的一个请求,因此,paxos可以被视为一个基于定序器的协议。按照paxos的术语,定序器被称为leader。从宏观的角度,一个使用paxos的复制状态机的执行按一系列paxos实例向前推进,即:
①在稳定状态中,客户端将请求发送给一个被选为leader的副本。propose将该请
求作为提案,并通过犘狉狅狆狅狊犲消息来协调所有非故障副本。如果犘狉狅狆
狅狊犲消息得到某个副本多数集(即2犳+1个副本以上)的确认并且犾犲犪犱犲狉收到它们的犪犮犮犲狆狋消息,则犾犲犪犱犲狉认为请求在多数副本间被商定,随后犾犲犪犱犲狉将商定的请求告知所有副本,所有副本就可以安全地执行该请求。最后,收到客户端请求的副本在执行请求后向客户端发送一个应答。
②当某个非犾犲犪犱犲狉副本怀疑犾犲犪犱犲狉已经失效时,它通过获得那些它认为命令尚未被提交的实例的所有权而尝试成为新的犾犲犪犱犲狉。为此,它发送犘狉犲狆犪狉犲消息给副本的至少一个简单多数集合。通过从副本多数集合收到的犃犮犽狀狅狑犾犲犱犵犲反馈,犾犲犪犱犲狉将获得在下一阶段可安全提出的提案值。以上针对稳定状态和犾犲犪犱犲狉失效的两个轮次执行的犘犪狓狅狊协议就是复制状态机的核心。
虽然局域环境下副本间的复制与同步可以通过复制状态机来实现,但是在跨多个数据中心的广域云架构下,为数据副本同时提供强一致性而同时保证高性能同步是一个困难的问题。这主要是由广域环境下保持副本强一致性需面对的两个制约因素决定的:犪)广域消息的高延迟传输。复制的执行通常是基于消息交换的,其性能受广域网络带宽和延迟的显著影响。在跨多个数据中心的副本间执行时所受影响尤甚。犫)不均衡的链路依赖。以犾犲犪犱犲狉为中心的犘犪狓狅狊由于其安全性和活性而成为实现复制状态机最受欢迎的协议。不过,由于唯一犾犲犪犱犲狉的存在,只有与犾犲犪犱犲狉处于相同数据中心的副本才会只通过局域网与其通信,而其他数据中心的副本则主要通过广域网与其通信,这使犾犲犪犱犲狉所在局域网大部分时间均处于空闲状态。这种不均衡的链路依赖关系极大制约了复制与同步的性能。
2、面向能源互联网的数据一致性框架
2.1 系统模型
本节对面向能源互联网、基于数据中心构建的云端架构进行建模,以便更清晰而有针对性地对将提出的框架进行描述。
面向能源互联网的、基于数据中心的云端架构可以被建模为由广域网互联的犿(犿3
)个数据中心,每个数据中心都包含一组共犇犻(犇犻≥3,犻=1,2,…,犿)台用于存放能源信息数据副本的服务器。支持上层应用的能源大数据在所有服务器上
均复制了相同的一份副本并进行一致性的读写,以便位于能源互联网广域范围内不同位置的应用客户端可以快速地、同步地访问相同的数据。
根据现实中网络链路的建设方式,面向不同微电网“局域网”的数据中心之间通过广域网络连接,这些连接可以被建模为两两独立连接的一组链路,它们的通信通常是延迟受限的;而位于相同微电网“局域网”的数据中心内部的服务器之间则通过局域网络连接,这些连接可以被建模为共享带宽的一组链路,它们的通信往往是带宽受限的。
2.2 框架概览
在上述系统模型的基础上为上层应用的快速访问提供一致的共享副本,就必须面向此模型设计一个能够提供高效资源利用和较高整体性能的复制状态机。在一个复制状态机中,如果针对副本的访问请求的全排序任务可以被划分为多个并行处理的部分排序子任务,且在所有服务器上执行一次全排序的开销远大于在部分服务器上执行部分排序子任务的开销,则通过将全排序任务划分为多个并行执行子任务将是一个有效的解决方案。
多台服务器可以执行一个局部一致性协议从而构建一个局部复制状态机,实现对访问请求的部分排序,形成部分有序的请求序列。局部复制状态机可以被视为一个逻辑实体。多个局部复制状态机可以一起运行一个全局一致性协议,进一步构建一个全局复制状态机,最终实现对所有部分有序请求序列的全排序。这种设计方式的好处在于,当需要在全局一致性协议的执行过程中等待广域范围内的反馈消息时,局部一致性协议可以继续执行对本地请求的部分排序,从而压缩各个副本空闲等待的时间。副本同步过程中采用的上述一致性协调架构与过程形成了一个数据一致性框架。在上文能源互联网典型场景下的数据一致性框架如图2所示。
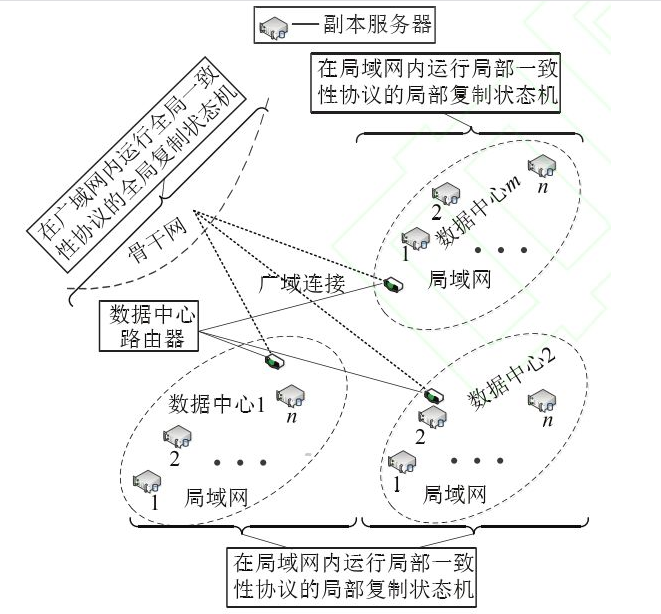
实际上,云架构中通常包含不止3个数据中心。如上一节的假设,数据中心的个数为犿(犿≥3),每个数据中心均包含犇犻≥3台服务器。在数据一致性框架中,每个局部复制状态机都作为一个逻辑实体。这些逻辑实体之间运行一个全局一致性协议以完成彼此间对部分有序请求序列的全局一致性协调,从而实现一个全局复制状态机。
具体实现在:
①一个局部复制状态机实际上扮演了全局一致性协议的一个角色,角色动作的具体执行是由某个物理对象作为代表完成的。在该局部复制状态机中,该物理对象是某台被选中的副本服务器,它被称为代理服务器。
②全局一致性协议排序的对象是由某个局部复制状态机部分排序形成的部分有序请求序列,而不是来自某个应用客户端的单个请求。
③不论是局部复制状态机还是全局复制状机都必须遵循复制状态机实现必须满足的终止、有效、完整和一致性。
2.3 框架中的一致性协议
在异步消息、非致命故障和采用最终完美的故障检测器的情况下,数据一致性框架为协调执行其局部复制状态机和全局复制状态机而对每个数据中心进行了初始化,每个数据中心都预先选择其中的某台服务器作为代理服务器。选举可以通过犾犲犪犱犲狉选举算法完成。
直观而言,数据一致性框架中的一致性协议包含了分别实现局部复制状态机和实现全局复制状态机的两个阶段:每个数据中心内的部分排序阶段(运行局部一致性协议)和所有数据中心间的全排序阶段(运行全局一致性协议)。为了使框架中的一致性协议高效运行,这两个阶段必须遵循如下约束规则:
规则A:每台代理服务器同时扮演三种不同角色。
首先,它作为局部一致性协议实例的局部协调者,在部分排序阶段中在本地执行指定数量的实例,从而产生部分有序的请求序列;
其次,它作为全局一致性协议实例的全局接受者,参与全排序阶段中全局一致性协议实例的协调;
最后,所有代理服务器在多个全局排序阶段中轮流作为全局一致性协议实例的全局协调者,协调全排序阶段中的全局一致性协议实例,获得全局有序的请求序列。
规则B:当某台代理服务器轮到担任全局协调者并启动一个全局一致性协议实例时,其他所有的代理服务器一致同意该代理服务器作为该实例的默认协调者并从它已经为某个初始轮次狉运行过阶段1(类似于犘犪狓狅狊实例的阶段1)的状态开始,即它们承诺不在任何小于狉的轮次中接受任何请求。
规则C:针对全局一致性协议实例定义了两种类型的提案。一种是非空的部分有序请求序列,另一种是空序列(代表保持数据不被改动并且不产生任何响应的请求)。规则要求,在执行全局一致性协议实例时,只有被分配了某个全局一致性协议实例的默认代理服务器才能提出非空的部分有序请求序列,其他的非默认的代理服务器在该实例中只能提出空序列。
根据上述规则,数据一致性框架中的一致性协议可以按照如下的两个阶段在所有数据中心交替执行:
a)数据中心内的部分排序阶段。它包括:
①各台代理服务器作为局部协调者持续接收来自应用客户端的请求。
②每台代理服务器执行多个局部一致性协议实例。执行后形成的部分有序请求序列
被写入本地稳定存储,并作为代理服务器协调的下一个全局一致性协议实例的提案。
b)数据中心间的全排序阶段。它包括:
①根据规则A,某台代理服务器轮到担任全局协调者。
②根据规则B和C,全局协调者将部分排序阶段形成的部分有序请求序列作为提案,发送给所有其他数据中心的代理服务器,并等待来自规定数量(半数以上)全局接受者的响应。
③当收到来自全局协调者的提案时,全局接受者将该消息记录到稳定存储,并检查其是否满足安全性约束条件,即:该数据中心尚未针对该全局一致性协议实例接受具有
更高轮次编号的提案;并且全局接受者将提案转发给本数据中心内的其他所有服务器并得到规定数量服务器的确认响应。如果条件满足,局部接受者就向全局协调者发回一个接受响应;否则,它不作出任何响应。
④一旦收到来自规定数量全局接受者的接受响应,全局协调者即获悉其提案被选中,并通过广播消息告知所有代理服务器,这些代理服务器则将该消息转发给其所在数据中心内的其他所有副本服务器。
框架中一致性协议的执行流程是直观的,即所有数据中心都轮流执行各自的全局排序阶段,而在每个数据中心未轮到协调其全局排序阶段时,则利用参与广域协调时广域消息传播形成的空闲时间执行其部分排序阶段。这使数据中心内部的空闲服务器资源和局域链路带宽得到更高效的利用,从而使整体上获得了较高的请求排序效率。
在云架构的实际运行过程中,数据中心的链路可能断开,而被选中的代理服务器也可能发生临时故障。在这些情况下,协议的有效运行必须通过相应的故障处置措施来得以保证。数据一致性框架针对这些情况设置了相应的处置措施:
措施A:当某个代理服务器发生故障或被错误怀疑发生了故障时,其所在数据中心通过重选举算法选举新的代理服务器,新的代理服务器通过询问该数据中心的其他副本服务器并获取相应的反馈来恢复此前发生故障的代理服务器所处的状态。
措施B:当某个数据中心发生故障时,允许其他数据中心代替它继续完成分配给该故障数据中心的全局一致性协议实例,作为替代的全局协调者收集来自其他代理服务器的响应。如果它收到法定数量代理服务器的一个非空的有序请求序列,则它将该序列作为提案提出,否则,它将提出空序列(根据规则犆)。
措施C:当某个数据中心被错误地怀疑发生了故障时,如果其为某个全局一致性协议实例提出了一个非空的有序请求序列,但却获知空序列被选中了,则它被允许在此后重新提出该非空的有序请求序列。
3、仿真结果
本节通过在Emulab上搭建的仿真环境对面向能源互联网的云架构数据一致性框架进行了性能评估。Emulab是一个可用于仿真大规模云架构的公共框架和实验设施,具有良好的控制能力和易用性,同时又具有较好的模拟真实性。
3.1 仿真设置
为了方便性能的比较与评估,仿真实验将运行本文所述一致性协议的数据一致性框架与分别运行犕狌犾狋犻犘犪狓狅狊和犕犲狀犮犻狌狊协议的普通复制状态机在吞吐量和可扩展性方面进行了比较。仿真实验给各个协议都施加了同样足够大的处理压力,这是通过为它们提供足够多的应用客户端请求来实现的。能源互联网应用被构造成一种只接受客户端请求而保持数据状态不变的简单服务。针对不同的仿真实验目的模拟了不同的配置环境。在配置最多的情况下,配置包含了5个数据中心,每个数据中心包含10到15台副本服务器。相同数据中心内的所有服务器通过一个延迟为025犿狊、有效带宽为920犕犻犫犻狋/狊的局域网络相连,所有数据中心则通过一个延迟为150犿狊、有效带宽为945犕犻犫犻狋/狊的广域网络相连。此外,每个数据中心还有一台用以发送应用客户端请求的服务器,请求的粒度是可配置的。
3.2 数据一致性处理的吞吐量
本节研究数据一致性框架相比较于普通复制状态机而言对吞吐量的提升程度。实验在3个数据中心进行,每个数据中心有10台副本服务器的配置,并采用了2048犅
、512犅和128犅的请求粒度。如图3所示。
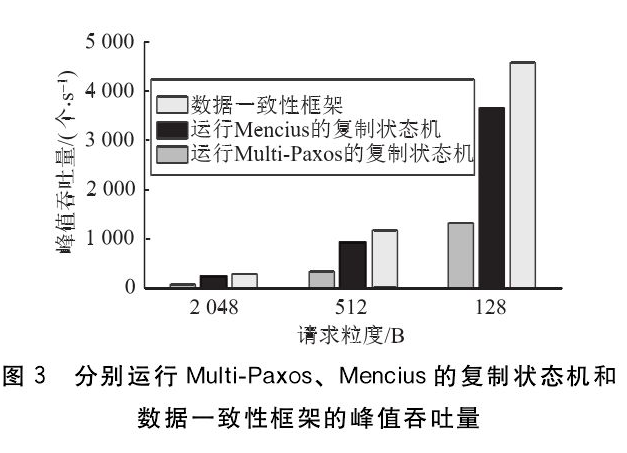
由图3可知,不论采用哪种请求粒度,数据一致性框架的峰值吞吐量均优于其他两种协议的峰值吞吐量。数据一致性框架的峰值吞吐量在请求粒度为128犅时,可以达到约4590个/狊的峰值吞吐量。这分别是运行了犕狌犾狋犻犘犪狓狅狊和犕犲狀犮犻狌狊的普通复制状态机的347倍和123倍。运行犕狌犾狋犻犘犪狓狅狊的普通复制状态机由于其唯一的犾犲犪犱犲狉受制于不均衡的链路依赖,其峰值吞吐量最低。运行犕犲狀犮犻狌狊的普通复制状态机通过使更多服务器分摊协调负载来获得较高的峰值吞吐量,但这也意味着在仿真的广域环境下需要传递更多的消息,从而限制了其性能的进一步提升。
相比之下,本文提出的数据一致性框架通过在每个数据中心上划分不同的执行阶段(部分排序阶段和全排序阶段),并结合轮转协调者方式来高效地利用数据中心间固有的广域传播高延迟而形成的空闲时间和带宽资源。部分排序阶段形成的有序请求序列可以在全排序阶段作为数据中心间的请求处理批次,从而提高了广域消息协调的效率;而轮转协调者机制则以逻辑流水线方式进一步提高了数据一致性框架的峰值吞吐量。
3.3 框架的可扩展能力
为了适应未来能源信息量的激增,面向能源互联网的云架构必须具备良好的可扩展性能。这意味着支撑云架构的数据一致性框架处理应用客户端请求的能力能够在数据中心或副本服务器数量增加的情况下不受到显著的影响。仿真实验通过在一组不同的配置下用普通复制状态机和数据一致性框架分别处理相同粒度的请求个数并记录其吞吐量来比较其可扩展性。

如图4所示,尽管所有解决方案在总副本数增加(或者增加数据中心数量,或增加每个数据中心内副本服务器数量)的情况下受到负面影响,不过,本文提出的数据一致性框架所受到的负面影响明显地小于分别运行犕狌犾狋犻犘犪狓狅狊和犕犲狀犮犻狌狊的两个复制状态机所受到的影响。在数据中心数量增加或者每个数据中心内副本服务器数量增加的情况下,运行犕狌犾狋犻犘犪狓狅狊和犕犲狀犮犻狌狊的复制状态机的性能下降,在这两种情况下服务器的总数都增加,这种结果导致了犕狌犾狋犻犘犪狓狅狊和犕犲狀犮犻狌狊中对请求一致性进行协调所需的法定数量集数量的增加和协调消息交互的复杂性提高,从而影响了复制状态机的吞吐量表现。相比较之下,数据一致性框架的吞吐量在数据中心数量增加的情况下降低了2%,而在每个数据中心内服务器数量增加的情况下几乎维持不变。对于前者而言,由于每个数据中心内服务器数量增加,对共享的局域带宽的争用发生恶化,从而导致部分排序阶段形成的有序请求序列长度减少并进而影响框架的整体吞吐量;对于后者而言,数据一致性框架的吞吐量水平得以维持主要是因为:当数据中心内副本服务器数量不变的情况下,数据中心数量的增加一方面增加了每个代理服务器在全排序阶段与其他数据中心间协调通信的独立广域链路的可用总带宽增加,另一方面也使得代理服务器轮转协调全排序阶段的周期延长了,这意味着每个数据中心可用于部分排序阶段形成部分有序序列的时间增加了。这两个方面的正面影响在极大程度上抵消了副本数增加造成协调消息数量增加的负面影响。
4、结束语
结合能源互联网典型场景下的配置,数据一致性框架在保证数据强一致性的同时体现了良好的吞吐量和可扩展性,是解决能源信息数据同步共享与一致性处理的一种有效的解决方案。今后的研究方向主要是将数据一致性框架与实际的能源互联网项目相结合,并对其采用的一致性协议进行针对性的扩展和改进,以验证它们在现实场景中的有效性与适应性。

责任编辑:沧海一笑
-

权威发布 | 新能源汽车产业顶层设计落地:鼓励“光储充放”,有序推进氢燃料供给体系建设
2020-11-03新能源,汽车,产业,设计 -

中国自主研制的“人造太阳”重力支撑设备正式启运
2020-09-14核聚变,ITER,核电 -

探索 | 既耗能又可供能的数据中心 打造融合型综合能源系统
2020-06-16综合能源服务,新能源消纳,能源互联网
-
新基建助推 数据中心建设将迎爆发期
2020-06-16数据中心,能源互联网,电力新基建 -

泛在电力物联网建设下看电网企业数据变现之路
2019-11-12泛在电力物联网 -

泛在电力物联网建设典型实践案例
2019-10-15泛在电力物联网案例



-
权威发布 | 新能源汽车产业顶层设计落地:鼓励“光储充放”,有序推进氢燃料供给体系建设
2020-11-03新能源,汽车,产业,设计 -
中国自主研制的“人造太阳”重力支撑设备正式启运
2020-09-14核聚变,ITER,核电 -

能源革命和电改政策红利将长期助力储能行业发展
-
探索 | 既耗能又可供能的数据中心 打造融合型综合能源系统
2020-06-16综合能源服务,新能源消纳,能源互联网 -

5G新基建助力智能电网发展
2020-06-125G,智能电网,配电网 -

从智能电网到智能城市