电力消费大数据智能分析技术——用电大数据分析平台
5.2.3 用电大数据分析平台
参照云计算技术体系结构与处理工具,并结合电力用户侧大数据分析的实际需要,搭建以分析计算为主的电力用户侧大数据管理平台,其基本架构如图5-24所示,分为应用层、私有云计算层、数据管理层。
此框架主要是结合云计算技术,利用 Hadoop搭建电力用户侧大数据管理平台,在平台上采用HDFS( Hadoop分布式文件系统)、HBase ( hadoop数据库)与Hive( Hadoop数据仓库工具)建立大数据存储系统,在平台上搭建 MapReduce并行化计算框架和 Spark内存并行化计算框架作为大数据计算分析系统,对电力用户侧的大数据进行分析。
数据管理层主要是对数据进行采集和集成整合。数据采集主要包括从智能电表、 SCADA系统和各种传感器中采集的数据,这些数据不仅包括电网内部的数据,还包括大量相关的数据,这些数据由不同产商的设备产生,模态千差万别,各单位数据口径不一,形成了海量异构数据流,加工整合困难。这些数据的集成整合主要是指将传统系统产生的数据迁移至私有云平台,进行高效的管理。
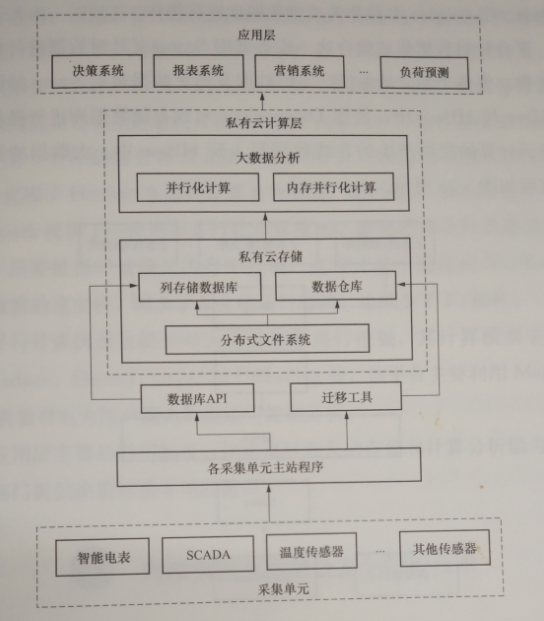
图5-24用电大数据分析架构
虽然各厂商都提供了相应的应用程序编程接口(application pro-gramming interface,API),但其自动化程度并不高。简单地使用API对大数据进行操作效率不高,需要使用第三方工具进行操作,如Sqoop和Datanucleus等。Sqoop是一款在Hadoop和关系数据库之间进行相互转移数据的工具,利用Sqoop可以使各个子系统的数据在大数据平台上进行整合。 Datanucleus是一款开源的java持久化工具,可以对HBase、 Cassandra多种非关系型数据库进行操作。
平台针对数据集成整合这一难点采用Sqoop工具对数据进行抽取整合工作,将各个独立的系统产生的数据及历史数据利用Sqoop抽取整合到Hive与HBase中。使用Datanucleus对列存储数据库进行操作,将基于云计算的应用产生的在线数据写入到HBase中。大数据的抽取整合流程如图5-25所示。
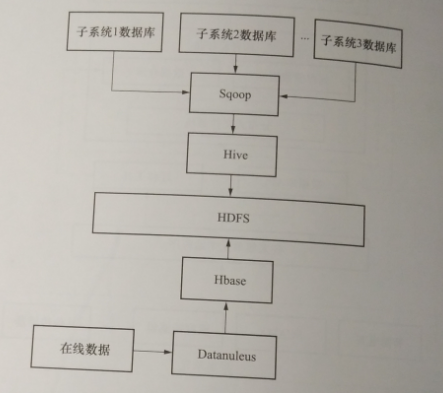
图5-25用电大数据整合抽取流程
云计算层利用Hadoop搭建而成,大数据存储在分布式文件系统HDFS中,利用Hive、Pig和HBase对数据进行管理,电力大数据在存储方面已进行了一些研究,例如有文献提出利用云计算存储、运算技术进行电力数据中心的搭建;有文献在云计算平台上将数据映射成数据空间的点集,充分利用计算存储资源,实现数据集到数据中心的布局方案;有文献在对数据进行存储时考虑到数据的安全性,利用HBase高性能优势和现代密码技术,将密钥与密文的管理分离,开发了基于Ha-doop的智能电网数据安全存储原型系统。该平台利用HBase存储电力负荷数据和相关数据, HBase数据库是列为存储单元的,方便对整列数据进行查询,而随后使用的随机森林算法在学习过程中需要多次对整列数据进行读取计算,对数据的操作需求符合HBase数据存储的特点。
利用并行化计算模型MapReduce对大数据进行并行化批量计算分析,而对数据密集型的迭代计算采用基于内存的并行化计算模型Spark。Spark是一个开源的分布式集群系统,用于大数据的快速处理分析。Spark克服了Hadoop在迭代计算上的不足,现已成为Apache的顶级项目。Spark提供了一种内存并行化计算框架,框架将作业所需数据读入内存,所需数据时直接从内存中查询,这样比基于磁盘的MapReduce访问数据的速度快,减少了作业的运行时间,也减少了IO操作。
并行计算模型主要是对大量的数据进行挖掘,其计算模型主要有MapReduce、Dremel、Dryad和Cascading等,该平台主要利用Map Re-duce模型对电力用户侧大数据进行挖掘分析。
应用层主要是利用私有云计算集群强大的存储和计算分析能力为企业各部门提供决策和指导功能接口。

责任编辑:电力交易小郭