电力消费大数据智能分析技术
电力消费大数据智能分析技术架构
随着能源互联网技术的发展和应用,互联网与用电行为逐步实现深度融合,体现在大量能源互联网数据、互联网用电行为数据、自然环境数据等多源异构数据共同支撑用电环节的网络化和智能化,包括节电负荷预测、错峰调度等电力消费相关大数据在类型、性质、形式和内容上均存在极大的差异。表现为显著的多源异构特性,虽然为进一步的分析与挖掘提供了丰富的可用信息,但由此带来的异构数据源的语义关联问题又使其面临着新的挑战。互联网环境下的电力消费大数据智能分析技术路线图如图5-17所示。本书针对能源互联网接入数据、互联网用电行为数据、地理社会环境数据的“规模庞大”和“异质多源”两个特性,为智能用电相关的大规模多源异构数据的融合和管理提供新原理与新方法,实现多源异构大数据的智能处理及高效运算。关键支撑技术主要包括:智能用电相关大数据的预处理及质量控制;针对智能用电相关大数据的分布式数据库架构的研究,以及多源异构大数据的融合及可视化;大规模多源异构数据的特征表示技术,以及大规模多源异构数据的关联分析模型建立;针对不同类型用户实现身份验证及安全访问控制等。

图5-17互联网环境下的电力消费大数据智能分析技术路线图
电力消费大数据处理流程
互联网环境下的电力消费相关大数据在采集以及传输过程中,都可能出现错误,产生噪声或空值。数据预处理可以改进数据的质量,消除数据的不完整性、冗余性和模糊性等,有助于保障挖掘过程中的数据精度和质量。
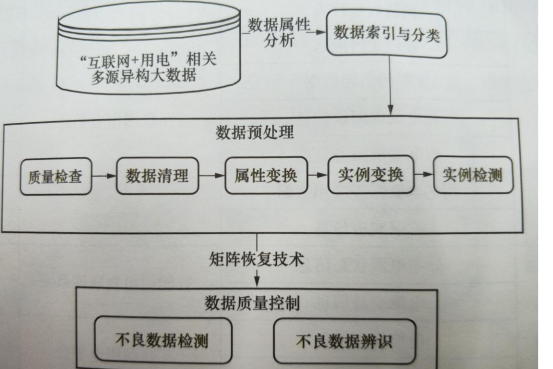
图5-18多源异构数据处理流程
由于互联网环境下的电力消费相关大数据的来源及组成不同,如图5-18所示,首先对数据进行属性的分析,并建立合适的属性索引和分类。然后,通过数据评估、数据重组、数据清洗、数据抽取、数据过滤、数据归约等六个模块分别对多源异构数据进行处理。这六个子模块先后作用于现实数据源,共同完成了现实数据源向系统使用的数据矩阵的转换。数据的评估和重组是数据预处理的前提。将数据源先清洗为适合挖掘的干净数据,然后根据数据集的大小确定是否需要进行数据抽取,再对数据集中不符合挖掘格式的数据进行数据过滤,若数据集中的冗余属性较多,则需要进行数据归约,经过这些数据预处理模块的处理后,保存为数据矩阵的格式,为后面的挖掘算法做好准备。并非所有数据源的数据都需要全部经过上述六个步骤的处理,具体操作视数据而定。
另外,在矩阵恢复理论框架下,建立多源数据的结构化低秩表示模型,表征多模态数据间的结构关系,通过矩阵的低秩与结构化稀疏性约束,能够从稀疏的显著误差中恢复出关系矩阵,从而实现数据的质量控制。
1.互联网环境下的电力消费数据属性与分类
互联网环境下的电力消费相关的大数据主要包括用户的社会属性、用电行为、能源互联网接入等信息,存在着各种结构化和非结构类型,在进行预处理和数据融合前需要对数据属性和类型进行分析,建立合适的属性索引和分类,为数据的预处理奠定基础,见表5-4。
表5-4 互联网环境下的电力消费数据属性和类型

2.数据预处理
互联网环境下的电力消费数据预处理的主要目的是使多源异构数据更易于数据挖掘等工作的高效计算,过程包括:
(1)质量检查。质量检查部分不会对数据进行任何修改,而是从一些客观的角度对数据进行衡量,如对属性的扫描、检查属性类型、检查数据的缺损状况等,对数据的衡量是数据分析的参考依据。
(2)数据清理。数据清理部分旨在处理数据源中的错误,如填充缺损值、平滑噪声数据、重复记录检测、孤立点检测等。
(3)属性变换。属性变换指的是对数据列的变换,包括对属性值的处理和属性类型的变换,如属性的增加与删除、有监督离散化和无监督离散化等。
(4)实例变换。实例变换指的是对数据行的变换,包括数据实例的增加与约简,如模拟数据的产生和数据的抽样等。
(5)实例检测。实例检测的目的在于发现一些特定的实例,如重复记录和孤立点(又称为离群点),这样的数据实例有时候也是数据分析的重点,如欺诈检测等。
数据预处理系统如图5-19所示,从整体上分为数据格式转换子系统、预处理算法实现环境子系统和数据管理子系统三个部分。从整体上看,系统的输入是一个数据文件,或者是一个数据库表,输出的结果是对其进行处理后的数据文件或者数据库表处理包括应用数据预处理算法对数据进行预处理,或者是格式转换。因此,系统被设计成为数据文件驱动型的,任何操作都必须建立在有可用的数据文件的前提下。
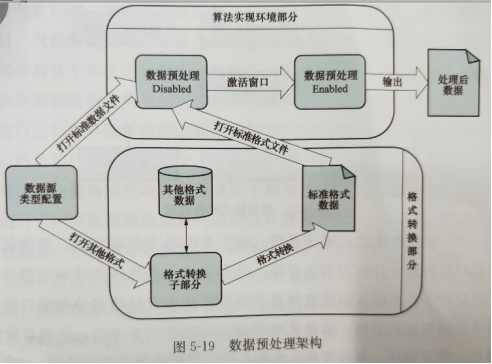
(1)格式转换子系统。由于大数据智能分析任务所需要的数据有可能来自许多不同的地方,因此数据的格式可能会千差万别大部分的数据都存储在数据库中,此外,也有等文件格式因此格式转换子系统主要功能就是将数据库表中的数据转换为格式,同时也能将一种数据库格式转换为其他数据库格式。
数据格式转换部分的架构如图5-20所示,由于涉及对各种数据库的访问,因此各种数据库的驱动程序应该集中存放在一起,并建立起各种数据库格式与驱动程序的映射由此构建数据库连接的管理,和数据库操作的管理通过获取数据库的架构信息,完成对数据库结构的解析,实现数据库在异构数据源中的重建与数据记录的转存。

(2)预处理算法实现子系统。由于系统是文件驱动的,算法的执行必须有数据文件在没有选择输入数据文件以前算法实现环境部分处于锁定状态,在输入数据文件后系统的算法实现环境部分的窗口就被激活根据前面的分析,算法实现环境部分包含六个方面,分别是质量检查、数据清理、属性变换、实例变换、属性选择和实例检测。此外,算法实现环境部分还包括对数据文件的操作和浏览等部分,如图5-21所示。

在进入预处理算法实现环境子系统之后,系统会要求打开一个数据文件打开的数据文件将存放到数据中心,这是系统统一管理数据的地方与此同时,系统会扫描数据文件中的一些基本信息,包括属性的数目、属性的类型等,并将这些信息显示到界面上打开文件后算法管理部分对各个算法进行激活,使得算法标签能够使用算法管理部分将算法负责算法的分类与调用如在开启算法界面的同时对算法需要的条件进行选择等算法管理部分起着对算法的调用的功能,算法在执行完相应的处理后会调用数据中心的相关功能实现对数据的修改和显示系统将所有的数据预处理算法分成四个部分,每个部分都是独立运行的在进行了一项数据预处理后可以接着对数据进行下一项预处理每次处理后数据中心都会对数据进行一次保存,用于操作的撤销与重做。
(3)数据管理子系统。数据管理部分需要完成的基本功能有数据的获取、数据查看、数据保存、数据历史管理等。如图5-22所示,数据管理部分提供两个接口,一是数据管理部分从数据文件中读取数据;二是提供一个接口使得算法能够方便的读取到数据。此外,还要保证各种算法使用的数据的统一性。

数据查看提供一个随时查看数据的一个界面,以表格的形式将数据展示给用户同时在界面上提供一些基本的数据操作功能(数据实例或者属性的插入删除修改等)数据的保存将算法处理后的数据保存起来,包括用户的保存和系统的自动保存两个方面,用户可以在任何时候自行保存中间数据,系统在对数据执行任何操作后都应该能回退到操作以前的状态,这需要保存功能和历史管理两部分的协同。
历史管理部分需要对系统的操作进行记录,在执行算法后需要记录下这次操作,并使用数据保存部分的功能对原始数据进行保存,对保存的数据和系统执行的操作进行关联。
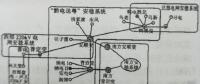
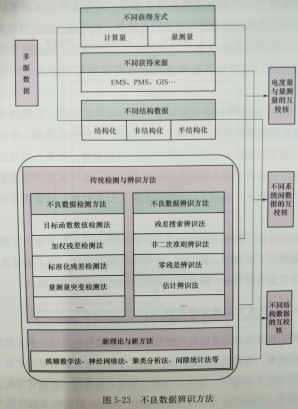
(4)数据质量控制。数据的质量关系到大数据的融合及相关关系分析的准确性,其关键环节是不良数据检测,即判断量测采样中是否存在不良数据。不良数据辨识是指在发现某次量测采样中存在不良数据后,确定哪个(或哪些)量测是不良数据。如图5-23所示,根据互联网环境下的电力消费大数据多源、多渠道的特点,基于不同来源的数据进行互校核,实现不良数据的检测与辨识,包括电度量和量测量的互校核、不同数据系统间的互校核方法、不同结构数据的互校核等。
1)基于电度量与量测量互校核的不良数据检测方法。按获得方式分,用电相关多源数据可划分为电度量与量测数据,可采用电度量与量测量互校核辨识不良数据。
如实际计算中,可用同一节点下电度量和有功量测进行互校核

(5-6)
![]() 式中:为I时刻该节点的有功电度量;PI-1、P1为I-1、I时刻该节点的有功功率;δ为准确系数,由实际量测系统准确度决定。
式中:为I时刻该节点的有功电度量;PI-1、P1为I-1、I时刻该节点的有功功率;δ为准确系数,由实际量测系统准确度决定。
2)基于不同系统间数据互校核的不良数据捡测方法。互联网环境下的电力消费相关多源数据按获得来源分,可分为来自不同系统的数据,来自不同系统间的数据可以进行互校核。如可结合配电网管理信息系统、生产管理系统的信息以及低压台区互联信息,确定配变用电类型,按照不同行业需量系数和典型日负荷曲线可拟合出该配变负荷曲线。
3)基于不同结构数据互校核的不良数据检测方法。互联网环境下的电力消费相关多源数据中含有结构化数据、非结构化数据、半结构化数据,但是不同类型的数据可能包含相同的信息量,如某一线路的长度可由地理信息系统中的非结构化图形数据获得,也可从生产管理系统中的结构化数据获得,通过不同类型的数据进行互校核,可实现不良数据的辨识互联网环境下的电力消费相关多源数据中不同的数据源为智能用电研究对象提供了多角度、多时间、多维度的数据描述,为了通过大数据分析充分挖掘有用信息,需要建立数据之间的关联数学模型。

责任编辑:售电小陈