《电力大数据》引发技术变革的电力大数据
1)红外图像存储模型。
HBase是一个分布式的、面向列的开源数据库,该技术来源于Fay Chang所撰写的论文“Bigtable:—个结构化数据的分布式存储系统”。就儀Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同是HBase是基于列的而不是基于行的模式。
HBase是采用KeyValue的列存储,Rowkey是KeyValue的Key,表示唯一一行。Rowkey是一段二进制码流,最大值为64KB,内客由用户自定义。数据的加载数据Rowkey的二进制序由小到大进行排序。HBase根据数据的规模将数据自动分切到多个Region的多个HFile中。

图3-18HBase物理存储架构
另外与传统的面向列的关系型数据库为基本单元不同,HBase的基本存储单元为列簇(columnfamily)。HBase数据逻辑上由行和列组成二维矩阵存储。其中由HBase的列簇、列组成了二维矩阵中的一维,由Rowkey组成了另一维,每一个非空的行列节点称为一个Cell,Cell是HRase最小的逻辑存储单元

图3-19 HBase逻辑存储架构
2)存储模型中Columnkey设计。
近似内聚原则:由于HBase是一个面向列簇的存储器,相同的列簇存储在同一个HRegion中,并交由对应的HRegionServer来管理。HBase从同一个HRegion获取数据的效率远高于从不同的HRegion中获取数据。目前使用中HBase的调优和存储都是在列簇这个层次上进行的,最好使列簇成员都有相同的访问模式(access pattern)和大小特征。
减少列簇原则:在一张表里不要定义太多的列簇。目前HBase并不能很好地处理超过3个列簇的表。因为某个列簇在flush的时候:它邻近的列簇也会因关联效应被触发flush,最终导致系统产生更多的I/O。
根据上述两个原则,结合红外图像诊断的实际业务,本数据存储模型分为3个列簇。

图3-20三个列簇
☆基本信息簇(f_info):存储图像对应设备名称、类型、所属厂站、上传时间、拍摄时间以及拍摄设备类型等基本信息。

图3-21图像基本信息簇
其中“processed”列为标识图像是否被预处理的标识位。
☆图像信息簇(f_img):以字节流形式存储图像全部信息。

图3-22图像信息簇
☆温度信息簇(f_temp):存储图像预处理后的各部位温度分析结果信息。
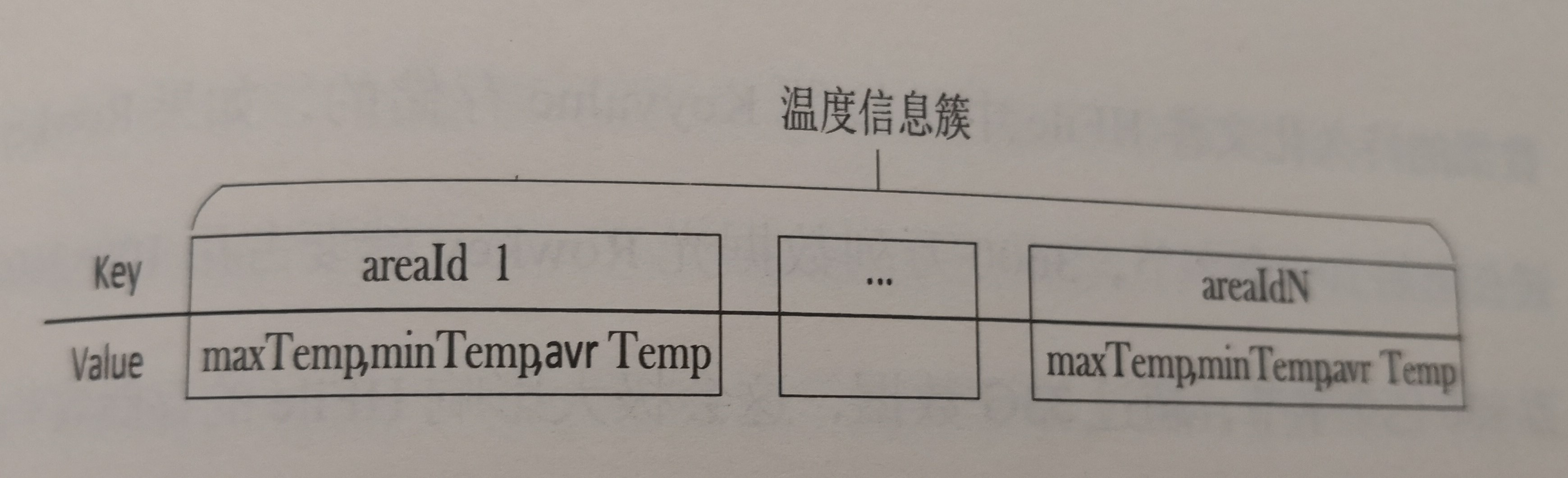
图3-23温度信息簇
每一列以Key-Value形式存储着图像中一个关系区域的温度分结果,其中Key为区域Id,Value存储着对应区域的最高温、最低温以及平均温度并以“,”分隔开。
3)存储模型中RowKey设计。
唯一原则:Rowkey作为一张图片的索引,唯一性是最基本的原则。不同于关系型数据库HBase中不支持对于关联关系的维护,在Rowkey的设计中一般不会采用无业务意义的流水ID、UUID等主键方式。HBase中Rowkey的设计往往需要结合业务需求,将多个有实时意义的属性拼接而成。结合红外图像诊断的实际业务,可以将设备名称、设备类型、设备所属站以及拍摄时间这几个属性拼接。
长度原则:Rowkey是一个二进制码流,理论上HBase支持最大的Rowkey为64KB,但原则上Rowkey的长度越短越好。原因一:数据的持久化文件HFile中是按照Keyvalue存储的,如果Rowkey过长比如100个字节,3600万列数据光Rowkey就要占用100x3600万=36亿个字节,超过33G数据,这会极大影响HFile的存储效率;原因二:MemStore将缓存部分数据到内存,如果Rowkey字段过长,内存的有效利用率会降低,系统将无法缓存更多的数据,这会降低检索效率。目前操作系统是都是64位系统,内存8字节对齐,在设计主键时应尽量使得Rowkey的长度为8的整数倍。
为了尽量减少Rowkey的长度,Rowkey一般不采用汉字,而采用数值型编码格式。结合电力系统的实时情况,一个地市厂站ID设为000〜999之间,设备类型在00~99之间,某一厂站下某一类型的设备ID设置在00~99之间。
离散原则:HBase的基本存储单元是HRegion,每个HRegion由相对的HRegionServer特定处理。HBase中的记录根据Rowkey序存储在不同的HRegion中,Rowkey越相近的记录存储在相同HRegion上的概率越大。如果一次查询中大部分数据集中在某个HRegion上会造成HRegionServer之间的负荷均衡问题,导致个别HRegionServer过热,降低查询效率。
结合到红外图像诊断系统中图像的拍摄时间(格式为yyMMddhhmm)最不适合作为Rowkey的高位。其他格式的时间例“mmhhyyMMdd”等虽然满足了离散原则,但由于查询的结果集根据Rowkey降序排列的,选用如此格式的时间将造成结果集的混乱,增加后序计算的难度。采用厂站ID作为Rowkey的高位面临同样的问题,将造成同一厂站内的图像存储在同一HRegion的概率增加。比较而言,设备ID以及设备类型ID作为Rowkey的高位比较合适。实际应用中,根据设备类型排序更有意义。
综上所述,本数据模型最终选择的Rowkey格式为:设备类型ID+“-”+厂站ID+“-”+拍摄时间+“-”+设备ID。为了便于检索,各类属性之间用“-”分隔开。
4)Rowkey的查询设计。
HBase的查询实现只提供两种方式:
A、按指定Rowkey获取唯一一条记录,get方法。
B、按指定的条件获取一批记录,scan方法。
对于第一种方法一次获取唯一一条记录,查询效率极高,但局限性也很大,需要知道详细的Rowkey值。此方法没有过多的优化空间。实现条件查询功能使用的就是scan方式,scan在使用时有以下几点值得注意:
A、scan可以通过setCatch与setBatch方法提高速度(以空间换时间)。
B、scan可以通过setStartROW与setEndROW方法来限定范围。范围越小,性能越高。
C、scan可以通过设计一个或者一组过滤器“Filter”对结果集进行过滤。
对于已知RowKey高位属性,可以通过简单地设置StartRow与EndRow以及添加过滤器的形式来实现高效査询。例如查询厂站ID为012,在2014年06月01号到2014年09月30号内所有开关(02)的红外图像,其对应的参数设置为
startRow=02-012-1406010000-00
endRow=02-012-l409302359-99
而对于Rowkey高位不确定的情况,则稍稍麻烦一点。例如查询一个厂站(012)在2014年06月01号到2014年09月30号内所有设备的红外图像,其对应的参数设置为
startRow=00-012-1406010000-00
endRow=99-012-1409302359-99
然后再设置一个正则表达式过滤器(RegexStringComparator),过滤掉不符合条件的数据。对应的正则表达式为
regStr=“\\w-\\012-140[6-9][0-l][l-9][0-2][0-9][0-5][0-9]-\\w”
5)基于HBase的图像数据模型优点。
基于HBase的图像模型存储,克服了传统关系型数据库+文件管理系统在安全性、扩展性以及一致性等方面缺点,也克服了基于HDFS小文件存储效率不高的缺点。本模型很好地实现了图像基本信息、图像信息、图像处理结果信息的一体化存储,并且利用HBase列存储的特性可实现了更多的业务扩展。
本存储模型结合实际业务需求,实现了对图像相关信息按拍摄时间、设备所属厂站、设备类型以及设备名称的快速模糊检索功能,为基于大数据的红外图像的分析与诊断提供了技术支撑。
书名:电力大数据:能源互联网时代的电力企业转型与价值创造
ISBN:978-7-111-51693-4
作者:赖征田
出版日期:2016-01
出版社:机械工业出版社

责任编辑:继电保护
-

权威发布 | 新能源汽车产业顶层设计落地:鼓励“光储充放”,有序推进氢燃料供给体系建设
2020-11-03新能源,汽车,产业,设计 -

中国自主研制的“人造太阳”重力支撑设备正式启运
2020-09-14核聚变,ITER,核电 -

探索 | 既耗能又可供能的数据中心 打造融合型综合能源系统
2020-06-16综合能源服务,新能源消纳,能源互联网
-
新基建助推 数据中心建设将迎爆发期
2020-06-16数据中心,能源互联网,电力新基建 -

泛在电力物联网建设下看电网企业数据变现之路
2019-11-12泛在电力物联网 -

泛在电力物联网建设典型实践案例
2019-10-15泛在电力物联网案例



-
权威发布 | 新能源汽车产业顶层设计落地:鼓励“光储充放”,有序推进氢燃料供给体系建设
2020-11-03新能源,汽车,产业,设计 -
中国自主研制的“人造太阳”重力支撑设备正式启运
2020-09-14核聚变,ITER,核电 -

能源革命和电改政策红利将长期助力储能行业发展
-
探索 | 既耗能又可供能的数据中心 打造融合型综合能源系统
2020-06-16综合能源服务,新能源消纳,能源互联网 -

5G新基建助力智能电网发展
2020-06-125G,智能电网,配电网 -

从智能电网到智能城市