大数据来袭,你准备好了吗
最近有一则这样的笑话在网上流程开来,有一个美国数学教授平生最怕坐飞机,他研究了近20年的统计数据,发现恐怖分子带炸弹上飞机的几率其实非常低,但是他还不安心,他又进一步研究数据发现,两个人同时带炸弹上
最近有一则这样的笑话在网上流程开来,“有一个美国数学教授平生最怕坐飞机,他研究了近20年的统计数据,发现恐怖分子带炸弹上飞机的几率其实非常低,但是他还不安心,他又进一步研究数据发现,两个人同时带炸弹上飞机的几率几乎为零,于是从此他坐飞机都自己携带一枚炸弹。”这虽然是一个简单笑话,但却是一个大数据分析的真实案例。这名科学家最终的做法固然可笑,但是在整个过程中,他收集整理了20年来与之相关的数据,包括天气数据、航班信息、新闻事件、乘客信息、出租车信息、交通信息、监控信息等等大量的相关数据,通过自己的研究,整理和分析了数据之间的相关性,构建了数据分析模型,并最终得出了分析结果。那么,什么才是大数据呢?
"大数据"是一个体量特别大,数据类别特别大的数据集,并且这样的数据集无法用传统数据库工具对其内容进行抓取、管理和处理。 "大数据"首先是指数据体量(volumes)?大,指代大型数据集,一般在10TB?规模左右,但在实际应用中,很多企业用户把多个数据集放在一起,已经形成了PB级的数据量;其次是指数据类别(variety)大,数据来自多种数据源,数据种类和格式日渐丰富,已冲破了以前所限定的结构化数据范畴,囊括了半结构化和非结构化数据。接着是数据处理速度(Velocity)快,在数据量非常庞大的情况下,也能够做到数据的实时处理。最后一个特点是指数据真实性(Veracity)高,随着社交数据、企业内容、交易与应用数据等新数据源的兴趣,传统数据源的局限被打破,企业愈发需要有效的信息之力以确保其真实性及安全性。
"大数据"的概念远不止大量的数据(TB)和处理大量数据的技术,而是涵盖了人们在大规模数据的基础上可以做的事情,而这些事情在小规模数据的基础上是无法实现的。换句话说,大数据让我们以一种前所未有的方式,通过对海量数据进行分析,获得有巨大价值的产品和服务,或深刻的洞见,最终形成创新之力。
由此可见,大数据的建设,我们首先要明确我们分析的目标,需要具备一个高性能的、大容量的具备数据采集、存储、分析和展现能力的那么一个平台或者系统。这就需要考虑以下几个问题:数据从何而来?海量的数据如何存储?这么多相关或非相关的数据怎么分析?分析出来结果如何展示?因此考虑上述问题,大数据分析不应该是一个系统,而应该一个平台,是一个可以收集存储不同格式不同规模的海量数据的高度数据共享的平台,是一个随时根据需求建立模型分析和展示不同结果的平台。
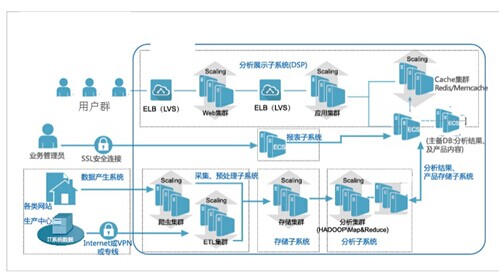
图1 大数据平台系统结构
1. 数据采集
大数据的采集是指利用多个数据库来接收发自客户端(Web、App或者传感器形式等)的数据,并且用户可以通过这些数据库来进行简单的查询和处理工作。比如使用传统的关系型数据库MySQL和Oracle等来存储数据,除此之外,Redis和MongoDB这样的NoSQL数据库也常用于数据的采集。
在大数据的采集过程中,其主要特点和挑战是并发数高,因为同时有可能会有成千上万的用户来进行访问和操作,比如火车票售票网站和淘宝,它们并发的访问量在峰值时达到上百万,所以需要在采集端部署大量数据库才能支撑。并且如何在这些数据库之间进行负载均衡和分片的确是需要深入的思考和设计。
2. 数据预处理
虽然采集端本身会有很多数据库,但是如果要对这些海量数据进行有效的分析,还是应该将这些来自前端的数据导入到一个集中的大型分布式数据库,或者分布式存储集群,并且可以在导入基础上做一些简单的清洗和预处理工作。导入与预处理过程的特点和挑战主要是导入的数据量大,每秒钟的导入量经常会达到百兆,甚至千兆级别。
3. 数据分析
统计与分析主要利用分布式数据库,或者分布式计算集群来对存储于其内的海量数据进行普通的分析和分类汇总等,以满足大多数常见的分析需求,在这方面,一些实时性需求会用到EMC的GreenPlum、Oracle的Exadata,以及基于MySQL的列式存储Infobright等,而一些批处理,或者基于半结构化数据的需求可以使用Hadoop。统计与分析这部分的主要特点和挑战是分析涉及的数据量大,其对系统资源,特别是I/O会有极大的占用。
4. 数据挖掘
与前面统计和分析过程不同的是,数据挖掘一般没有什么预先设定好的主题,主要是在现有数据上面进行基于各种算法的计算,从而起到预测(Predict)的效果,从而实现一些高级别数据分析的需求。比较典型算法有用于聚类的Kmeans、用于统计学习的SVM和用于分类的NaiveBayes,主要使用的工具有Hadoop的Mahout等。该过程的特点和挑战主要是用于挖掘的算法很复杂,并且计算涉及的数据量和计算量都很大,常用数据挖掘算法都以单线程为主。
5. 结果呈现
当通过分析子系统对数据分析和处理完毕,需要从在独立的数据库存放计算和分析结果,并最终通过分析展示子系统将分析结果展现给数据需求者。分析展示子系统采用B/S架构构建一个Web应用,可以是更多的用户以最便捷的方式查看到分析结果。
上述内容就是普遍的一个大数据分析的基本步骤,大数据分析平台是运用了多种技术构建的一个整体,对基础设施建设具有很高要求,也是实现大数据分析平台的关键,而分析模型和方法建立则是大数据分析的核心,其中每一个环节都包含了大量技术应用。例如:
数据采集:ETL工具负责将分布的、异构数据源中的数据如关系数据、平面数据文件等抽取到临时中间层后进行清洗、转换、集成,最后加载到数据仓库或数据集市中,成为联机分析处理、数据挖掘的基础。
数据存取:关系数据库、NOSQL、SQL等。
基础架构:云存储、分布式文件存储等。
数据处理:自然语言处理(NLP,NaturalLanguageProcessing)是研究人与计算机交互的语言问题的一门学科。处理自然语言的关键是要让计算机"理解"自然语言,所以自然语言处理又叫做自然语言理解(NLU,NaturalLanguage Understanding),也称为计算语言学(Computational Linguistics。一方面它是语言信息处理的一个分支,另一方面它是人工智能(AI, Artificial Intelligence)的核心课题之一。
统计分析:假设检验、显著性检验、差异分析、相关分析、T检验、方差分析、卡方分析、偏相关分析、距离分析、回归分析、简单回归分析、多元回归分析、逐步回归、回归预测与残差分析、岭回归、logistic回归分析、曲线估计、因子分析、聚类分析、主成分分析、因子分析、快速聚类法与聚类法、判别分析、对应分析、多元对应分析(最优尺度分析)、bootstrap技术等等。
数据挖掘:分类 (Classification)、估计(Estimation)、预测(Prediction)、相关性分组或关联规则(Affinity grouping or association rules)、聚类(Clustering)、描述和可视化、Description and Visualization)、复杂数据类型挖掘(Text, Web ,图形图像,视频,音频等)
模型预测:预测模型、机器学习、建模仿真。
结果呈现:云计算、标签云、关系图等。(彭勇)
"大数据"是一个体量特别大,数据类别特别大的数据集,并且这样的数据集无法用传统数据库工具对其内容进行抓取、管理和处理。 "大数据"首先是指数据体量(volumes)?大,指代大型数据集,一般在10TB?规模左右,但在实际应用中,很多企业用户把多个数据集放在一起,已经形成了PB级的数据量;其次是指数据类别(variety)大,数据来自多种数据源,数据种类和格式日渐丰富,已冲破了以前所限定的结构化数据范畴,囊括了半结构化和非结构化数据。接着是数据处理速度(Velocity)快,在数据量非常庞大的情况下,也能够做到数据的实时处理。最后一个特点是指数据真实性(Veracity)高,随着社交数据、企业内容、交易与应用数据等新数据源的兴趣,传统数据源的局限被打破,企业愈发需要有效的信息之力以确保其真实性及安全性。
"大数据"的概念远不止大量的数据(TB)和处理大量数据的技术,而是涵盖了人们在大规模数据的基础上可以做的事情,而这些事情在小规模数据的基础上是无法实现的。换句话说,大数据让我们以一种前所未有的方式,通过对海量数据进行分析,获得有巨大价值的产品和服务,或深刻的洞见,最终形成创新之力。
由此可见,大数据的建设,我们首先要明确我们分析的目标,需要具备一个高性能的、大容量的具备数据采集、存储、分析和展现能力的那么一个平台或者系统。这就需要考虑以下几个问题:数据从何而来?海量的数据如何存储?这么多相关或非相关的数据怎么分析?分析出来结果如何展示?因此考虑上述问题,大数据分析不应该是一个系统,而应该一个平台,是一个可以收集存储不同格式不同规模的海量数据的高度数据共享的平台,是一个随时根据需求建立模型分析和展示不同结果的平台。
图1 大数据平台系统结构
大数据的采集是指利用多个数据库来接收发自客户端(Web、App或者传感器形式等)的数据,并且用户可以通过这些数据库来进行简单的查询和处理工作。比如使用传统的关系型数据库MySQL和Oracle等来存储数据,除此之外,Redis和MongoDB这样的NoSQL数据库也常用于数据的采集。
在大数据的采集过程中,其主要特点和挑战是并发数高,因为同时有可能会有成千上万的用户来进行访问和操作,比如火车票售票网站和淘宝,它们并发的访问量在峰值时达到上百万,所以需要在采集端部署大量数据库才能支撑。并且如何在这些数据库之间进行负载均衡和分片的确是需要深入的思考和设计。
2. 数据预处理
虽然采集端本身会有很多数据库,但是如果要对这些海量数据进行有效的分析,还是应该将这些来自前端的数据导入到一个集中的大型分布式数据库,或者分布式存储集群,并且可以在导入基础上做一些简单的清洗和预处理工作。导入与预处理过程的特点和挑战主要是导入的数据量大,每秒钟的导入量经常会达到百兆,甚至千兆级别。
3. 数据分析
统计与分析主要利用分布式数据库,或者分布式计算集群来对存储于其内的海量数据进行普通的分析和分类汇总等,以满足大多数常见的分析需求,在这方面,一些实时性需求会用到EMC的GreenPlum、Oracle的Exadata,以及基于MySQL的列式存储Infobright等,而一些批处理,或者基于半结构化数据的需求可以使用Hadoop。统计与分析这部分的主要特点和挑战是分析涉及的数据量大,其对系统资源,特别是I/O会有极大的占用。
4. 数据挖掘
与前面统计和分析过程不同的是,数据挖掘一般没有什么预先设定好的主题,主要是在现有数据上面进行基于各种算法的计算,从而起到预测(Predict)的效果,从而实现一些高级别数据分析的需求。比较典型算法有用于聚类的Kmeans、用于统计学习的SVM和用于分类的NaiveBayes,主要使用的工具有Hadoop的Mahout等。该过程的特点和挑战主要是用于挖掘的算法很复杂,并且计算涉及的数据量和计算量都很大,常用数据挖掘算法都以单线程为主。
5. 结果呈现
当通过分析子系统对数据分析和处理完毕,需要从在独立的数据库存放计算和分析结果,并最终通过分析展示子系统将分析结果展现给数据需求者。分析展示子系统采用B/S架构构建一个Web应用,可以是更多的用户以最便捷的方式查看到分析结果。
上述内容就是普遍的一个大数据分析的基本步骤,大数据分析平台是运用了多种技术构建的一个整体,对基础设施建设具有很高要求,也是实现大数据分析平台的关键,而分析模型和方法建立则是大数据分析的核心,其中每一个环节都包含了大量技术应用。例如:
数据采集:ETL工具负责将分布的、异构数据源中的数据如关系数据、平面数据文件等抽取到临时中间层后进行清洗、转换、集成,最后加载到数据仓库或数据集市中,成为联机分析处理、数据挖掘的基础。
数据存取:关系数据库、NOSQL、SQL等。
基础架构:云存储、分布式文件存储等。
数据处理:自然语言处理(NLP,NaturalLanguageProcessing)是研究人与计算机交互的语言问题的一门学科。处理自然语言的关键是要让计算机"理解"自然语言,所以自然语言处理又叫做自然语言理解(NLU,NaturalLanguage Understanding),也称为计算语言学(Computational Linguistics。一方面它是语言信息处理的一个分支,另一方面它是人工智能(AI, Artificial Intelligence)的核心课题之一。
统计分析:假设检验、显著性检验、差异分析、相关分析、T检验、方差分析、卡方分析、偏相关分析、距离分析、回归分析、简单回归分析、多元回归分析、逐步回归、回归预测与残差分析、岭回归、logistic回归分析、曲线估计、因子分析、聚类分析、主成分分析、因子分析、快速聚类法与聚类法、判别分析、对应分析、多元对应分析(最优尺度分析)、bootstrap技术等等。
数据挖掘:分类 (Classification)、估计(Estimation)、预测(Prediction)、相关性分组或关联规则(Affinity grouping or association rules)、聚类(Clustering)、描述和可视化、Description and Visualization)、复杂数据类型挖掘(Text, Web ,图形图像,视频,音频等)
模型预测:预测模型、机器学习、建模仿真。
结果呈现:云计算、标签云、关系图等。(彭勇)

责任编辑:叶雨田
免责声明:本文仅代表作者个人观点,与本站无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
我要收藏
个赞
-

权威发布 | 新能源汽车产业顶层设计落地:鼓励“光储充放”,有序推进氢燃料供给体系建设
2020-11-03新能源,汽车,产业,设计 -

中国自主研制的“人造太阳”重力支撑设备正式启运
2020-09-14核聚变,ITER,核电 -

探索 | 既耗能又可供能的数据中心 打造融合型综合能源系统
2020-06-16综合能源服务,新能源消纳,能源互联网
-
新基建助推 数据中心建设将迎爆发期
2020-06-16数据中心,能源互联网,电力新基建 -

泛在电力物联网建设下看电网企业数据变现之路
2019-11-12泛在电力物联网 -

泛在电力物联网建设典型实践案例
2019-10-15泛在电力物联网案例



-
权威发布 | 新能源汽车产业顶层设计落地:鼓励“光储充放”,有序推进氢燃料供给体系建设
2020-11-03新能源,汽车,产业,设计 -
中国自主研制的“人造太阳”重力支撑设备正式启运
2020-09-14核聚变,ITER,核电 -

能源革命和电改政策红利将长期助力储能行业发展
-
探索 | 既耗能又可供能的数据中心 打造融合型综合能源系统
2020-06-16综合能源服务,新能源消纳,能源互联网 -

5G新基建助力智能电网发展
2020-06-125G,智能电网,配电网 -

从智能电网到智能城市