大数据时代下的迁移学习
在这篇博文中,你将了解到什么是迁移学习,它的一些应用以及它为什么能够成为数据科学家应具备的关键技能。
迁移学习不是机器学习的一个模型或技术,它是机器学习中的一种“设计方法论”,还有一些其他的设方法论,比如说主动学习。

本文是AI科技大本营编译的迁移学习系列的第一篇文章。第二篇文章也会在近期放送给大家,其中讨论了迁移学习的两种应用。
在后续的文章中,作者将解释如何结合主动学习与迁移学习来最优地利用现有(或者新的)数据。 从广义上说,在利用外部信息来提高性能或泛化能力时,可以使用迁移学习来实现一些机器学习的应用。
▌迁移学习的定义
迁移学习的总体思路是:对于带大量标签数据及可用参数设置的源任务,迁移已学习的知识,处理带少量标签的目标任务。因为标记数据的成本是昂贵的,最佳地利用现有数据集来解决目标任务是关键。
在传统的机器学习模型中,主要目标是将训练数据中学习到的模式,推广到未知的数据。 通过迁移学习,你可以尝试从已经学习的任务模式开始,启动这个泛化过程。本质上,这不是从无到有地(通常是随机初始化的)开始学习过程,而是在学会了其他任务模式的基础上开始学习新任务。

能够从图像中区分线条和形状(左),这些特征能够更容易确定图中是否是“汽车”。可以运用迁移学习来学习其他计算机视觉模型中的模式,而不必从图像的原始像素值开始。

存在不同的方法来表示自然语言中的单词(词嵌入像左、右侧的词表示)。借助词嵌入算法,机器学习模型就可以利用不同单词之间存在的关系。
知识和模式的迁移在各种领域都是有可能实现的。这篇文章将通过几个不同领域的例子来说明迁移学习是如何工作的。我们的目标是鼓励数据科学家在机器学习项目中使用迁移学习,并让他们意识到这种方法的优缺点。
对于迁移学习的理解,以下这三个方面是我认为数据科学家都应具备的关键技能:
在任何一种学习模式中,迁移学习的应用都是至关重要的。为了获得成功,人类不可能学习到每一个任务或问题。每个人都会遇到从未遇到过的情况,但我们仍然希望以特殊的方式解决问题。从大量的经验中学习,并将“知识”转移到新环境中的能力正是迁移学习的关键所在。从这个角度来看,迁移学习和泛化能力在概念层面上是非常相似的。它们的主要区别在于迁移学习经常被用于“跨任务迁移知识,而不是在一个特定的任务中进行概括”。因此,迁移学习与所有机器学习模型所必需的泛化能力概念有着内在联系。
对于小数据量情况下深度学习技术,应用迁移学习是取得成功的关键。在实际研究中,深度学习几乎是无处不在,但是对于很多现实生活场景来说,通常都没有数百万个带标签的数据来训练模型。而深度学习技术需要大量的数据来调整神经网络中的数百万个参数,特别是在监督式学习的情况下。这就意味着你需要大量带标签数据来训练模型,而标注数据则需要昂贵的人工成本。标记图像听起来很平常的,但是在诸如自然语言处理(NLP)任务中,需要专家知识才能创建大型标记数据集。例如,Penn treebank是一个词性标注语料库,至今已有7年的历史了,它需要与多位语言学专家的密切合作才能完成。为保证小数据量上的神经网络能够正常运行,迁移学习是一种可行的方法。而其他可行的选择正朝着更多概率启发的模式发展,这些模式通常更适合处理有限的小数据集。
迁移学习有着显著的优点和缺点。了解这些缺点对于机器学习应用程序的成功是至关重要。知识迁移只有在“适当”的情况下才有可能。这种情况下,确切地定义“适当”的概念是不容易的,需要点经验知识来帮助确定。例如,你不应该相信一个在玩具车里开车的孩子能够开上法拉利。迁移学习的原理也是一样的:虽然它很难被量化,但迁移学习也是有上限的,也就是说它不是一个适合所有问题的解决方案。
▌迁移学习的一般概念
迁移学习的要求
正如它的名字,迁移学习需要将知识从一个领域迁移到另一个领域的能力。通常,迁移学习可以在高层级上进行解释。例如,自然语言处理任务中的体系结构可以在序列预测问题中重复使用,因为很多自然语言处理问题本质上都可以归结为序列预测问题。迁移学习也可以在低层级上进行解释,例如在实际中你经常会重复使用不同模型中的参数(跳过词组,连续词袋等)。迁移学习的要求,一方面是针对具体的问题而定,另一方面则是由具体的模型决定。接下来的两节将分别讨论迁移学习在高层级和低层级的应用方法。尽管在文献中通常会用不同的名字来阐述这些概念,但是迁移学习的总体概念仍然存在。
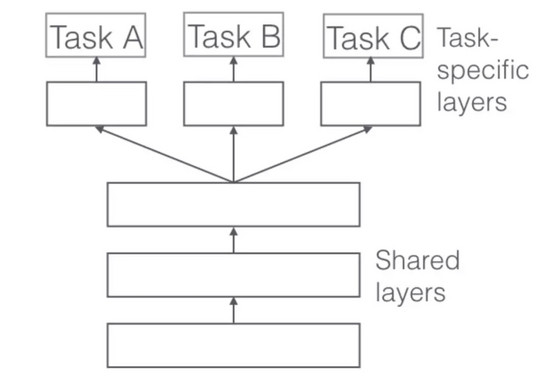
多任务学习
在多任务学习中,你可以同时在不同的任务上训练模型,通常这些都是深度学习模型,因为它们可以灵活地进行调整。
网络体系结构是这样调整的:第一层跨越不同的任务使用,随后为不同的任务指定特定的任务层和输出。总体的思路是,通过对不同任务的网络进行训练,网络将更好地推广,因为模型需要在相似的“知识”或“处理”任务上表现良好。
例如,自然语言处理任务的最终目标是执行实体识别的模型,而不是在实体识别任务纯粹地训练模型。你还用它来处理一部分语音分类,词语联想等任务……因此,模型将从不用的结构、不同的任务和不同的数据集的学习中获益。如果你想学习更多关于多任务学习的内容,强烈建议你阅读Sebastian Ruder的关于多任务学习的博文(http://ruder.io/multi-task/)。
▌ 特征提取
深度学习模型的一大优点是能够“自动化”地提取特征。基于标记的数据和反向传播法则,网络能够捕捉到对任务有用的特征。例如,对于图像分类任务,网络会计算出输入的哪一部分是重要的。这意味着手动定义的特征是很抽象的,而深度神经网络学习到的特征可以在其他问题中重复地使用。因为网络所提取的特征类型,常常对其他问题也是有用。本质上,你可以使用网络的第一层来确定有用的特征,但是你不能在其他任务上使用网络的输出,因为这些输出是针对特定任务的。
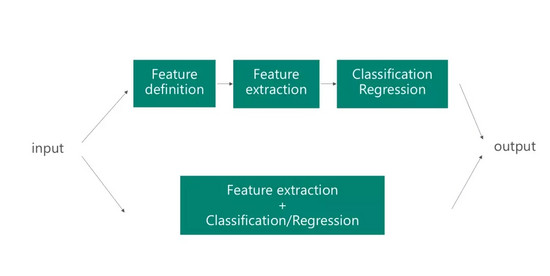
考虑到深度学习系统强大的特征提取能力,如何重复使用现有网络来执行其他任务的特征提取?
这里有一个方法,可以将新的数据样本馈送到网络中,并将网络中的一个中间层作为输出。这个中间层可以被设置为一个固定的长度,来表示原始数据的输出。特别地,在计算机视觉领域使用图像特征,馈送到预训练好的网络(例如,VGG或AlexNet),并在新的数据表示上使用不同的机器学习方法。提取中间层作为图像的表示能够显著地减少了原始数据大小,以便它们更适合于传统的机器学习技术(例如,对于一个128×128的小图像:大小为128×128=16384像素,逻辑回归算法或支持向量机通常有更好的算法性能)。
在接下来的博文中,作者还将深入讨论转移学习两种的应用,并用具体的例子来进一步说明,AI科技大本营将持续编译,欢迎继续关注。

责任编辑:马丽芳
-

权威发布 | 新能源汽车产业顶层设计落地:鼓励“光储充放”,有序推进氢燃料供给体系建设
2020-11-03新能源,汽车,产业,设计 -

中国自主研制的“人造太阳”重力支撑设备正式启运
2020-09-14核聚变,ITER,核电 -

探索 | 既耗能又可供能的数据中心 打造融合型综合能源系统
2020-06-16综合能源服务,新能源消纳,能源互联网
-
新基建助推 数据中心建设将迎爆发期
2020-06-16数据中心,能源互联网,电力新基建 -

泛在电力物联网建设下看电网企业数据变现之路
2019-11-12泛在电力物联网 -

泛在电力物联网建设典型实践案例
2019-10-15泛在电力物联网案例



-
权威发布 | 新能源汽车产业顶层设计落地:鼓励“光储充放”,有序推进氢燃料供给体系建设
2020-11-03新能源,汽车,产业,设计 -
中国自主研制的“人造太阳”重力支撑设备正式启运
2020-09-14核聚变,ITER,核电 -

能源革命和电改政策红利将长期助力储能行业发展
-
探索 | 既耗能又可供能的数据中心 打造融合型综合能源系统
2020-06-16综合能源服务,新能源消纳,能源互联网 -

5G新基建助力智能电网发展
2020-06-125G,智能电网,配电网 -

从智能电网到智能城市