数据科学家必须要掌握的5种聚类算法
聚类是一种将数据点按一定规则分群的机器学习技术。
给定一组数据点,我们可以使用聚类算法将每个数据点分类到一个特定的簇中。理论上,属于同一类的数据点应具有相似的属性或特征,而不同类中的数据点应具有差异很大的属性或特征。
聚类属于无监督学习中的一种方法,也是一种在许多领域中用于统计数据分析的常用技术。在数据科学中,我们可以使用聚类分析,来获得一些有价值的信息。其手段是在应用聚类算法时,查看数据点会落入哪些类。
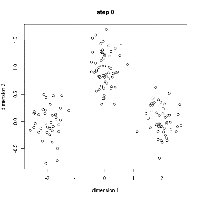
现在,我们来看看数据科学家们需要掌握的5种常见聚类算法以及它们的优缺点! ▌K-均值聚类 K-Means可能是最知名的聚类算法,没有之一。在很多介绍性的数据科学和机器学习课程中,都有讲授该算法。并且该算法的代码很容易理解和实现!你可以通过看下面的插图来理解它。
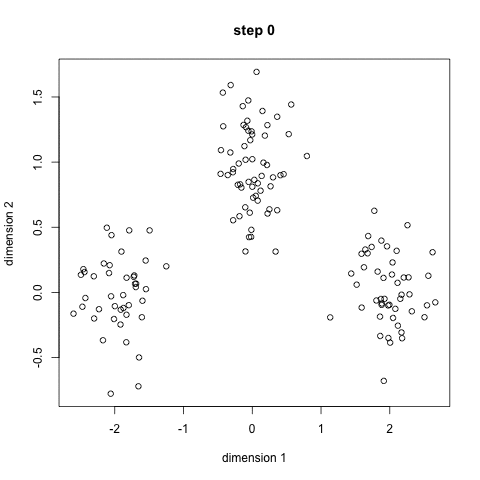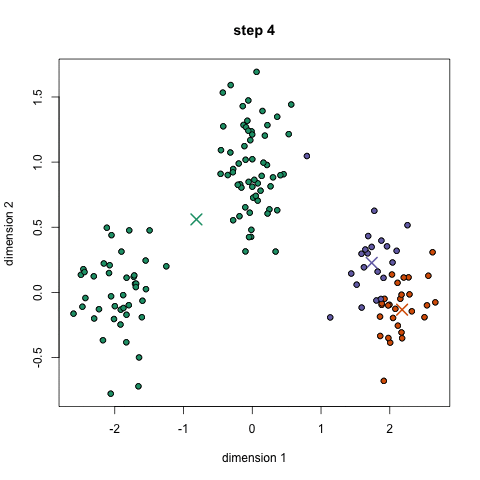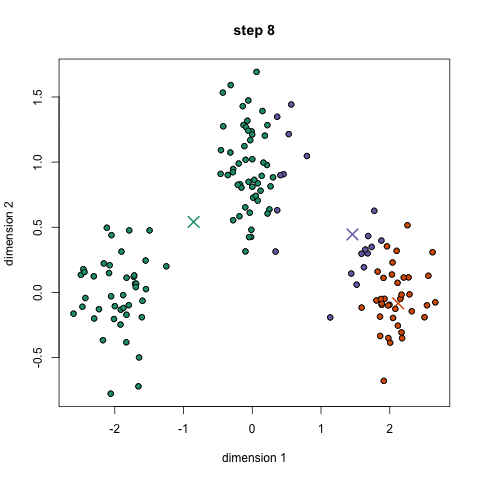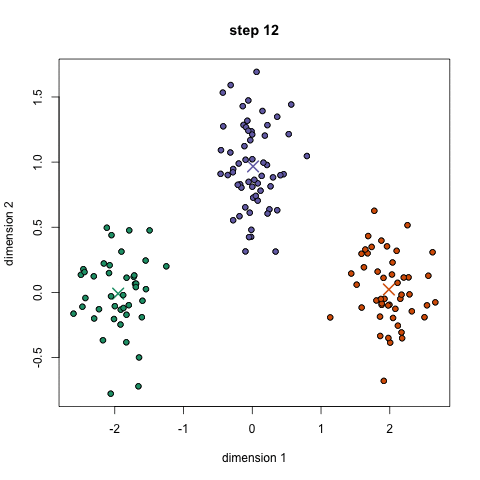
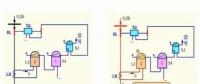
K均值聚类
1、首先,我们选择一些要使用的类/组,并随机初始化他们各自的中心点(质心)。要计算出簇(类)的使用数量,最好的方法是快速查看一下数据并尝试鉴别有多少不同的分组。中心点是一个矢量,它到每个数据点的矢量长度相同,在上图中用“X”来表示。 2、每个数据点通过计算该点与每个簇中心之间的距离来进行分类,根据最小距离,将该点分类到对应中心点的簇中。 3、根据这些已分类的点,我们重新计算簇中所有向量的均值,来确定新的中心点。 4、重复以上步骤来进行一定数量的迭代,或者直到簇中心点在迭代之间变化不大。你也可以选择多次随机初始化簇中心点,然后选择看起来像是最佳结果的数据,再来重复以上步骤。 K-Means算法的优势在于它的速度非常快,因为我们所做的只是计算点和簇中心之间的距离; 这已经是非常少的计算了!因此它具有线性的复杂度O(n)。 但是,K-Means算法也是有一些缺点。首先,你必须手动选择有多少簇。
这是一个很大的弊端,理想情况下,我们是希望能使用一个聚类算法来帮助我们找出有多少簇,因为聚类算法的目的就是从数据中来获得一些有用信息。
K-means算法的另一个缺点是从随机选择的簇中心点开始运行,这导致每一次运行该算法可能产生不同的聚类结果。
因此,该算法结果可能具有不可重复,缺乏一致性等性质。而其他聚类算法的结果则会显得更一致一些。 K-Medians是与K-Means类似的另一种聚类算法,它是通过计算类中所有向量的中值,而不是平均值,来确定簇的中心点。
这种方法的优点是对数据中的异常值不太敏感,但是在较大的数据集时进行聚类时,速度要慢得多,造成这种现象的原因是这种方法每次迭代时,都需要对数据进行排序。 ▌Mean-Shift聚类算法 Mean-Shift是一种基于滑动窗口的聚类算法。也可以说它是一种基于质心的算法,这意思是它是通过计算滑动窗口中的均值来更新中心点的候选框,以此达到找到每个簇中心点的目的。然后在剩下的处理阶段中,对这些候选窗口进行滤波以消除近似或重复的窗口,找到最终的中心点及其对应的簇。看看下面的图解。
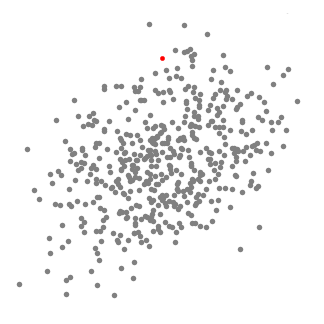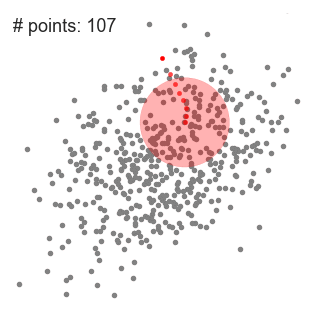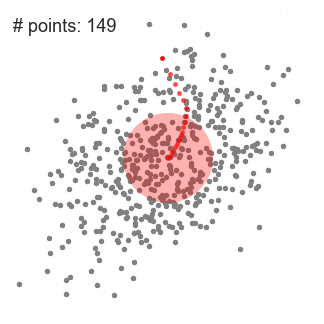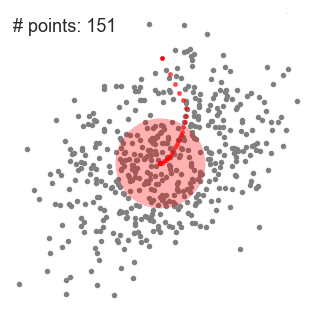
用于单个滑动窗口的Mean-Shift聚类算法
1、为了阐释Mean-shift算法,我们可以考虑二维空间中的一组点,如上图所示。我们从一个以C点(随机选择)为中心,以半径r为核心的圆滑动窗口开始。Mean-shift可以看作是一种等高线算法,在每次迭代中,它能将核函数(圆滑动窗口)移动到每个迭代中较高密度的区域,直至收敛。 2、在每次迭代中,通过将中心点移动到窗口内点的平均值处(因此得名),来使滑动窗口移向更高密度的区域。滑动窗口内的数据密度与其内部点的数目成正比。当然,通过移动窗口中点的平均值,它(滑动窗口)就会逐渐移向点密度更高的区域。 3、我们继续根据平均值来移动滑动窗口,直到不能找到一个移动方向,使滑动窗口可以容纳更多的点。看看上面图片的动画效果;直到滑动窗口内不再增加密度(即窗口中的点数),我们才停止移动这个圆圈。 4、步骤1至步骤3的过程是由许多滑动窗口来完成的,直到所有的点都能位于对应窗口内时才停止。当多个滑动窗口重叠时,该算法就保留包含最多点的窗口。最终所有数据点根据它们所在的滑动窗口来确定分到哪一类。 下图显示了所有滑动窗口从头到尾的整个移动过程。每个黑点代表滑动窗口的质心,每个灰点代表一个数据点。

Mean-Shift聚类的整个过程
与K-means聚类算法相比,Mean-shift算法是不需要选择簇的数量,因为它是自动找寻有几类。这是一个相比其他算法巨大的优点。而且该算法的聚类效果也是非常理想的,在自然数据驱动的情况下,它能非常直观的展现和符合其意义。算法的缺点是固定了窗口大小/半径“r”。 ▌基于密度的噪声应用空间聚类(DBSCAN) DBSCAN是一种基于密度的聚类算法,类似于Mean-shift算法,但具有一些显着的优点。我们从看下面这个奇特的图形开始了解该算法。
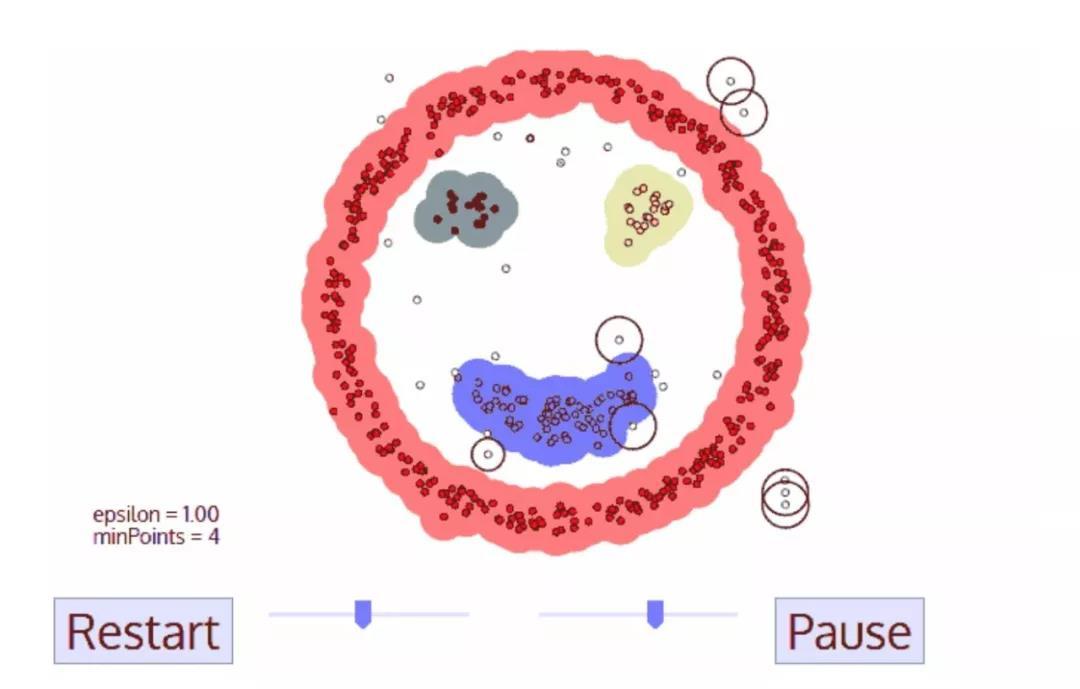
DBSCAN笑脸人脸聚类
1、DBSCAN算法从一个未被访问的任意的数据点开始。这个点的邻域是用距离epsilon来定义(即该点ε距离范围内的所有点都是邻域点)。 2、如果在该邻域内有足够数量的点(根据minPoints的值),则聚类过程开始,并且当前数据点成为新簇中的第一个点。否则,该点将被标记为噪声(稍后,这个噪声点可能成为聚类中的一部分)。在这两种情况下,该点都会被标记为“已访问”。 3、对于新簇中的第一个点,它的ε距离邻域内的点也会成为同簇的一部分。这个过程使ε邻域内的所有点都属于同一个簇,然后对才添加到簇中的所有新点重复上述过程。 4、重复步骤2和3两个过程直到确定了聚类中的所有点才停止,即访问和标记了聚类的ε邻域内的所有点。 5、一旦我们完成了当前的聚类,就检索和处理新的未访问的点,就能进一步发现新的簇或者是噪声。重复上述过程,直到所有点被标记为已访问才停止。由于所有点已经被访问完毕,每个点都被标记为属于一个簇或是噪声。 与其他聚类算法相比,DBSCAN具有很多优点。首先,它根本不需要确定簇的数量。不同于Mean-shift算法,当数据点非常不同时,会将它们单纯地引入簇中,DBSCAN能将异常值识别为噪声。另外,它能够很好地找到任意大小和任意形状的簇。 DBSCAN算法的主要缺点是,当数据簇密度不均匀时,它的效果不如其他算法好。这是因为当密度变化时,用于识别邻近点的距离阈值ε和minPoints的设置将随着簇而变化。在处理高维数据时也会出现这种缺点,因为难以估计距离阈值ε。 ▌使用高斯混合模型(GMM)的期望最大化(EM)聚类 K-Means算法的主要缺点之一就是它对于聚类中心平均值的使用太单一。
通过查看下面的图例,我们可以明白为什么它不是使用均值最佳的方式。
在左侧,人眼看起来非常明显的是,具有相同均值的数据中心点,却是不同半径长度的两个圆形簇。
而K-Means算法不能解决这样的数据问题,因为这些簇的均值是非常接近的。
K-Means算法在簇不是圆形的情况下也一样无效,也是由于使用均值作为集群中心。
K-Means算法两个失败的案例
相较于K-means算法,高斯混合模型(GMMs)能处理更多的情况。对于GMM,我们假设数据点是高斯分布的; 这是一个限制较少的假设,而不是用均值来表示它们是圆形的。这样,我们有两个参数来描述簇的形状:即均值和标准差!以二维为例,这意味着这些簇可以是任何类型的椭圆形(因为GMM在x和y方向上都有标准偏差)。因此,每个高斯分布都被单个簇所指定。 为了找到每个簇的高斯参数(例如平均值和标准差),我们将使用期望最大化(EM)的优化算法。请看下面的图表,可以作为匹配簇的高斯图的阐释。然后我们来完成使用GMM的期望最大化聚类过程。
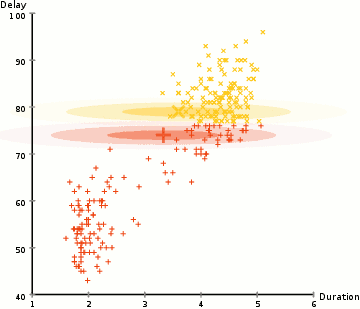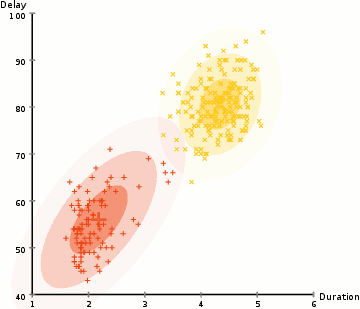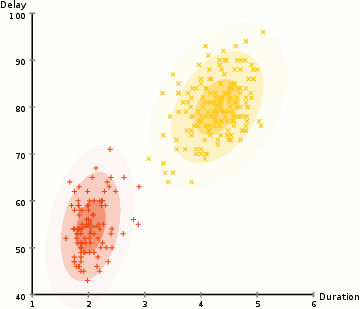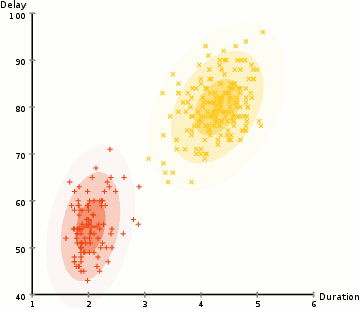
使用GMM的EM聚类
1、我们首先选择簇的数量(如K-Means),然后随机初始化每个簇的高斯分布参数。可以通过快速查看数据的方式,来尝试为初始参数提供一个较好的猜测。不过请注意,从上图可以看出,这不是100%必要的,因为即使是从一个很差的高斯分布开始,算法也能很快的优化它。 2、给定每个簇的高斯分布,计算每个数据点属于特定簇的概率。一个点越靠近高斯的中心,它越可能属于该簇。在使用高斯分布时这应该是非常直观的,因为我们假设大部分数据更靠近簇的中心。 3、基于这些概率,我们为高斯分布计算一组新的参数,使得我们能最大化簇内数据点的概率。我们使用数据点位置的加权和来计算这些新参数,其中权重是数据点属于该特定簇的概率。为了更直观的解释这个,我们可以看看上面的图片,特别是黄色的簇。第一次迭代时,分布是随机开始,但是我们可以看到大部分黄点都在分布的右侧。当我们计算按概率加权的和时,即使中心附近的点大部分都在右边,通过分配的均值自然就会接近这些点。我们也可以看到,大部分数据点都是“从右上到左下”。因此,改变标准差的值,可以找到一个更适合这些点的椭圆,以最大化概率加权的总和。 4、重复迭步骤2和3,直到收敛,也就是分布在迭代中基本再无变化。 使用GMM方法有两个很重要的优点。 首先,GMM方法在聚类协方差上比K-Means灵活得多; 由于使用了标准偏差参数,簇可以呈现任何椭圆形状,而不是被限制为圆形。 K-mean算法实际上是GMM的一个特殊情况,即每个簇的协方差在所有维度上都接近0。其次,由于GMM使用了概率,每个数据点可以有多个簇。因此,如果一个数据点位于两个重叠的簇的中间,我们可以简单地定义它的类,即属于类1的概率是百分之X,属于类2的概率是百分之Y。即,GMM支持混合类这种情况。 ▌凝聚层次聚类 分层聚类算法实际上分为两类:自上而下或自下而上。
自下而上的算法首先将每个数据点视为一个单一的簇,然后连续地合并(或聚合)成对的簇,直到所有的簇都合并成一个包含所有数据点的簇。
因此,自下而上的分层聚类被称为合成聚类或HAC。
这个簇的层次可以用树(或树状图)表示。树的根是收集所有样本的唯一簇,叶是仅具有一个样本的簇。
在进入算法步骤之前,请查看下面的图解。
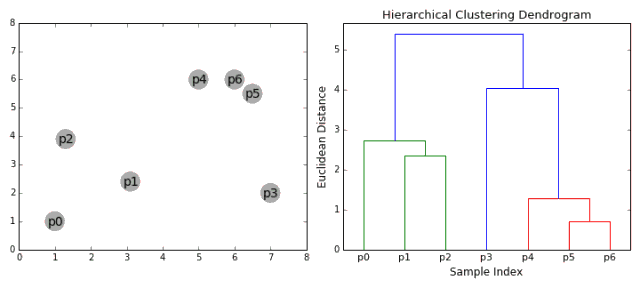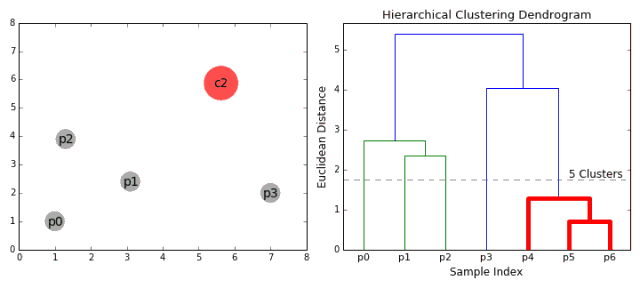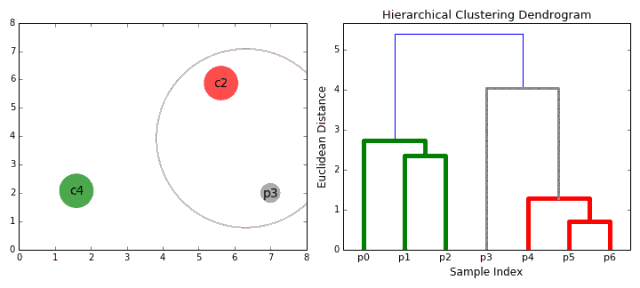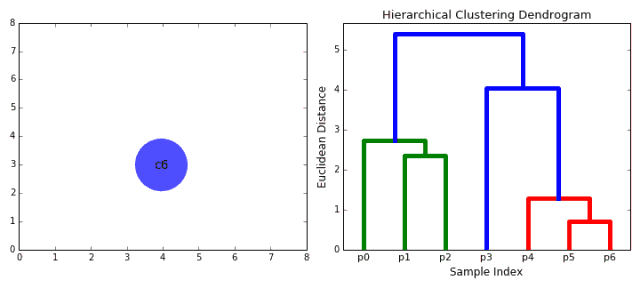
合成聚类
1、我们首先将每个数据点视为一个单一的簇,即如果我们的数据集中有X个数据点,那么我们就有X个簇。然后,我们选择一个距离度量,来度量两个簇之间距离。作为一个例子,我们将使用平均关联度量,它将两个簇之间的距离定义为第一个簇中的数据点与第二个簇中的数据点之间的平均距离。 2、在每次迭代中,我们将两个簇合并成一个簇。选择平均关联值最小的两个簇进行合并。根据我们选择的距离度量,这两个簇之间的距离最小,因此是最相似的,所有应该合并。 3、重复步骤2直到我们到达树的根,即我们只有一个包含所有数据点的簇。通过这种方式,我们可以选择最终需要多少个簇。方法就是选择何时停止合并簇,即停止构建树时! 分层次聚类不需要我们指定簇的数量,我们甚至可以在构建树的同时,选择一个看起来效果最好的簇的数量。
另外,该算法对距离度量的选择并不敏感;
与其他距离度量选择很重要的聚类算法相比,该算法下的所有距离度量方法都表现得很好。
当基础数据具有层次结构,并且想要恢复层次结构时,层次聚类算法能实现这一目标;
而其他聚类算法则不能做到这一点。
与K-Means和GMM的线性复杂性不同,层次聚类的这些优点是以较低的效率为代价,即它具有O(n3)的时间复杂度。

责任编辑:售电衡衡


-

十张图了解七大国产汽车2017年报看点:新能源汽车布局多
-
谈造车:谁能最先量产 谁就是“王者”
2018-04-20最先量产 -

合资股比50%底线背后 我们在担心什么?
2018-04-20合资股比





-
数据科学家必须要掌握的5种聚类算法
2018-04-23聚类算法 -

全面了解电力电缆
2018-04-23电力电缆 -

人工智能走进边缘,物联网应用落地加速