展望2018 AI芯片领域:众多厂商追随深度学习
Gwennap表示,Graphcore(英国布里斯托尔)和Cerebras(美国加州洛斯阿尔托)是训练芯片领域值得关注的两家初创公司,因为这两家公司筹集的资金最多,而且似乎拥有最好的团队。由Google前芯片设计师创立的初创公司Groq声称,它将在2018年推出一款推理芯片,在总体操作和每秒推论方面都会以4倍的优势击败竞争对手。
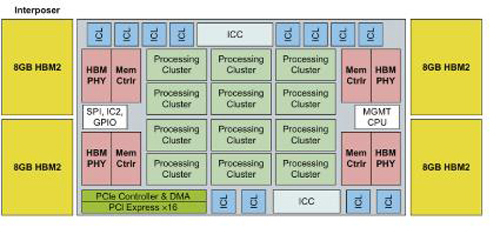
英特尔的Nervana是一个大型的线性代数加速器,位于4个8-Gb HBM2内存堆栈旁的硅中介层上。来源:Hennessy和Patterson,“计算机体系结构:一种定量方法”
英特尔代号为“Lake Crest”的Nervana(上图)是最受关注的定制设计之一。它执行16位矩阵操作,数据共享指令集中提供的单个5位指数。
与Nvidia Volta一样,Lake Crest逻辑器件位于4个HBM2高带宽内存堆栈旁边的TSMC CoWoS(衬底上芯片上芯片)中介层上。这些芯片被设计成网状,提供5到10倍于Volta的性能。
虽然去年微软在深度神经网络上使用了FPGA,但Patterson仍然对这种方法持怀疑态度。 “你为[FPGA的]灵活性付出了很多代价;编程真的很难,”他说。
Gwennap在去年年底的一项分析中指出,DSP也将发挥作用。Cadence、Ceva和Synopsys都提供面向神经网络的DSP内核,他说。
加速器缺乏共同的基准
这些芯片即将到来时,架构师们却还不确定如何评估这些芯片。
Patterson回忆说,就像RISC处理器的早期,“每个公司都会说,'你不要相信别人的基准,但是你可以相信我的',这可不太好。”
那个时候,RISC厂商们在SPEC基准测试中进行合作。现在,深度神经网络加速器需要自己定义的测试套件,涵盖各种数据类型的训练和推理,以及独立芯片和集群芯片。
听到这个呼吁,Transaction Processing Performance Council(TPC)在12月12日宣布成立了一个工作组来定义机器学习的硬件和软件基准。TCP是由20多个顶级服务器和软件制造商组成的团体。TPC-AI委员会主席Raghu Nambiar表示,这么做的目标是创建各种测试,并且这些测试不关乎加速器是CPU还是GPU。但是,这个团队的成员名单和时间框架还在不断变化之中。
百度在2016年9月发布了一个基于其深度学习工作负载的开放源代码基准测试工具,使用32位浮点数学做训练任务。百度在6月份更新了DeepBench以涵盖推理工作和16位数学的使用。
由哈佛大学研究人员发表的Fathom套件中,定义了8个人工智能工作负载,支持整数和浮点数据。Patterson表示:“这是一个开始,但是要获得一个让人感觉舒适的、全面的基准测试套件还需要更多的工作。”
“如果我们致力于打造一个很好的基准,那么所有用在这个工程上的钱都是物有所值的。”
除了基准之外,工程师还需要追踪仍在演变的神经网络算法,以确保他们的设计不会被淘汰。

责任编辑:任我行
-

碳中和战略|赵英民副部长致辞全文
2020-10-19碳中和,碳排放,赵英民 -

两部门:推广不停电作业技术 减少停电时间和停电次数
2020-09-28获得电力,供电可靠性,供电企业 -
国家发改委、国家能源局:推广不停电作业技术 减少停电时间和停电次数
2020-09-28获得电力,供电可靠性,供电企业
-
碳中和战略|赵英民副部长致辞全文
2020-10-19碳中和,碳排放,赵英民 -

深度报告 | 基于分类监管与当量协同的碳市场框架设计方案
2020-07-21碳市场,碳排放,碳交易 -

碳市场让重庆能源转型与经济发展并进
2020-07-21碳市场,碳排放,重庆
-
两部门:推广不停电作业技术 减少停电时间和停电次数
2020-09-28获得电力,供电可靠性,供电企业 -
国家发改委、国家能源局:推广不停电作业技术 减少停电时间和停电次数
2020-09-28获得电力,供电可靠性,供电企业 -
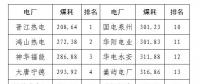
2020年二季度福建省统调燃煤电厂节能减排信息披露
2020-07-21火电环保,燃煤电厂,超低排放
-

四川“专线供电”身陷违法困境
2019-12-16专线供电 -
我国能源替代规范法律问题研究(上)
2019-10-31能源替代规范法律 -

区域链结构对于数据中心有什么影响?这个影响是好是坏呢!