警惕利用机器学习实施网络犯罪
机器学习 被定义为(计算机)没有明确编程的学习能力,这对于 信息安全 行业来说是一个巨大进步。这项技术可以帮助安全分析师从恶意软件
“他们将能够相互交流,并根据当地情报采取行动。“另外, 僵尸网络 会变得聪明,根据命令行事,而无需人工操纵。
因此,蜂巢网络将能够以群集的速度成倍增长,扩大其同时攻击多个受害者的能力,并显着阻碍防守方的缓解和响应动作。“
有趣的是,Manky说这些攻击还没有使用swarm技术,这项可以使这些蜂巢网络Hivenet从他们过去的行为中自我学习。作为人工智能的一个子领域,swarm技术被定义为“分散的、自组织的系统,自然的或人造的集体行为”,现在已经用于无人机和羽翼未丰的机器人设备中。(编者按:虽然是未来派的小说,但有些人可以从“Black Mirror’s Hated in The Nation ”中的swarm技术的犯罪可能性中得出结论,那里有成千上万的自动化蜜蜂,因为监视和物理攻击而受到威胁。)
3.先进的鱼叉式网络钓鱼邮件变得更聪明
敌对机器学习的一个更明显的应用,是使用文本到语音转换、语音识别和自然语言处理(NLP)等智能 社会工程 算法。毕竟,通过经常性的神经网络,你已经可以形成这样的软件写作风格,所以理论上 钓鱼邮件 可以变得更复杂和可信。
特别是,机器学习可以促进高级鱼叉式 网络钓鱼 电子邮件针对高调的数字,同时整个过程自动化。系统可以接受真正的电子邮件培训,并学习如何使看起来和阅读的东西令人信服。
在McAfee Labs对2017年的预测中,该公司表示,犯罪分子将越来越多地利用机器学习来分析大量被盗记录,从而识别潜在的受害者,并能够针对这些个人,构建非常有效地、内容详尽的电子邮件。
此外,在2016年美国黑帽会议上,John Seymour和Philip Tully发表了一篇名为“社会工程数据科学的武器化:Twitter上的自动化E2E鱼叉式网络钓鱼”的论文,其中介绍了一种经常性的神经网络,学习如何向特定用户发布网络钓鱼信息。在这篇论文中,他们提出经过 鱼叉式攻击 钓鱼 渗透测试 数据训练的SNAP_R神经网络,是动态的从目标用户时间线帖子(以及他们发送或者关注的用户)中获取主题,以便更容易触发潜在受害者点击链接。
随后的测试表明,这个系统非常有效。在涉及90个用户的测试中,该框架的成功率在30%到60%之间变化,对手动钓鱼和群发钓鱼的结果有相当大的改进。
4.威胁情报可能被“提高噪声基线”技术糊弄
在机器学习方面, 威胁情报 可以说是一种混合的祝福。一方面,普遍接受的是,在误报时代,机器学习系统将有助于分析人员识别来自多个系统的真实威胁。Recorded Future首席技术官兼联合创始人StaffanTruvé在最近的一份白皮书中表示:
“应用机器学习在威胁情报领域有两个显着的增长。
“首先,处理和构建如此庞大的数据,包括对其中复杂关系的分析,几乎不可能单靠人力来解决。用更有能力的人来训练机器,意味着你可以更有效的武装起来,比以往任何时候都更有能力揭示和回应新出现的威胁。”
“其次是自动化 - 让机器承担人类可以毫无问题地完成的任务,并利用这项技术扩大到更大的数量处理量。”
然而,也有这样的信念,即犯罪分子会再次适应这些警报。迈克菲的Grobman之前曾指出过一种被称为“提高噪声基线”的技术。黑客会利用这种技术来轰击环境,从而对常见的机器学习模型产生大量的误报。一旦目标重新校准其系统以滤除误报,攻击者就可以发起真正的攻击,可以通过机器学习系统获得。(小编,嗯?这是个挺有意思的想法,对于机器自学习及安全基线的设备有影响)
5.更有效的进行未授权访问
2012年,研究人员Claudia Cruz,Fernando Uceda和Leobardo Reyes 发表了一个机器学习安全攻击的早期例子。他们使用支持向量机(SVM)来打破在reCAPTCHA图像上运行的系统,精度为82%。所有验证码机制随后得到改进,只有研究人员再次深入学习才能打破验证码。2016年,发表了一篇文章,详细介绍了如何使用深度学习以92%的准确率打破简单验证码。
另外,去年 BlackHat 的“我是机器人”研究揭示了研究人员如何打破最新的语义图像CAPTCHA,并比较了各种机器学习算法。该文件承诺打破Google的reCAPTCHA准确率为98%。2017年10月, unCAPTCHA和AIBot成功突破google recapcha验证码, 5秒多突破450个成功率85%
6.对机器学习引擎的输入数据投毒
一个更加简单而有效的技术是,用于检测恶意软件的机器学习引擎可能被毒害,使得它不起作用,就像过去犯罪分子对反病毒引擎所做的一样。这听起来很简单,机器学习模型从输入数据中学习,如果数据池中毒,则输出也中毒。来自纽约大学的研究人员展示了卷积 神经网络 (CNN)如何能够通过CNN如Google、微软和AWS产生这些虚假(但受控制的)结果

责任编辑:任我行
免责声明:本文仅代表作者个人观点,与本站无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
我要收藏
个赞
-

碳中和战略|赵英民副部长致辞全文
2020-10-19碳中和,碳排放,赵英民 -

两部门:推广不停电作业技术 减少停电时间和停电次数
2020-09-28获得电力,供电可靠性,供电企业 -
国家发改委、国家能源局:推广不停电作业技术 减少停电时间和停电次数
2020-09-28获得电力,供电可靠性,供电企业
-
碳中和战略|赵英民副部长致辞全文
2020-10-19碳中和,碳排放,赵英民 -

深度报告 | 基于分类监管与当量协同的碳市场框架设计方案
2020-07-21碳市场,碳排放,碳交易 -

碳市场让重庆能源转型与经济发展并进
2020-07-21碳市场,碳排放,重庆
-
两部门:推广不停电作业技术 减少停电时间和停电次数
2020-09-28获得电力,供电可靠性,供电企业 -
国家发改委、国家能源局:推广不停电作业技术 减少停电时间和停电次数
2020-09-28获得电力,供电可靠性,供电企业 -
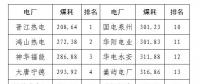
2020年二季度福建省统调燃煤电厂节能减排信息披露
2020-07-21火电环保,燃煤电厂,超低排放
-

四川“专线供电”身陷违法困境
2019-12-16专线供电 -
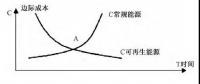
我国能源替代规范法律问题研究(上)
2019-10-31能源替代规范法律 -

区域链结构对于数据中心有什么影响?这个影响是好是坏呢!