云计算环境中的数据挖掘存储管理设计
1 引言 Hadoop提供了一个基于HDFs的简单数据库HBase,它的设计思想和数据模型都与Google开发的模型简化的大规模分布式数据库BigTabIe极为相似。HBase不支持完全的关系数据模型,只为用户提供了简单的数据模型,
1.引言
Hadoop提供了一个基于HDFs的简单数据库HBase,它的设计思想和数据模型都与Google开发的模型简化的大规模分布式数据库BigTabIe极为相似。HBase不支持完全的关系数据模型,只为用户提供了简单的数据模型,让客户来动态控制数据的分布和格式。从数据模型角度看,HBase是一个稀疏的、长期存储的(存在硬盘上)、多维度的、排序的映射表。这张表的索引是行关键字、列关键字和时间戳。每个值是一个不解释的字符数组,用户需要自己解释存储的字串的类型和含义。这种模型具有很大的灵活性,通过仔细选择数据表示,用户可以控制数据的局部化。但是这种灵活性的代价就是不支持完全的关系数据模型,这导致传统的数据存储格式无法应用于HBase。Google自身的GFS是为网页搜索功能量身定做的,采用BigTable的简单数据模型可以以字符串形式灵活存储网页的URL、时间戳等信息。HDFS的设计完全借鉴了GFS的思想,因此从目前的版本来看,HDFS对网页搜索具有较好的支持,但是对于使用传统的关系数据模型的产品来说,HDFS并不是一个很好的选择,因为它不能提供传统的关系数据库的相关功能。如上所述,以Hadoop为例,目前的开源解决方案并不完全适用于某公司的新产品需求,因此我们需要参照现有解决方案,设计符合自身需要的新方案。
2.DDF的数据划分策略
面对大量的异构的用户数据,我们有必要对数据进行划分,以期得到更好的查询性能。
数据划分策略可分为垂直数据划分(Horizontal panition)和水平数据划分(VerticaI partition),在DDF中同时采用了这两种划分策略。垂直数据划分是按照功能划分:
(1)首先把对象数据、查询数据和其他数据划分到不同的数据表中(数据库的表)。
(2)对于对象数据,由于是按对象类型(Object type)访问的,那么我们可以进一步按照对象类型进行垂直划分,把不同类型的对象数据划分到相应的数据表中。
(3)对于查询数据,在目前的研究阶段,也将其按照对象类型进行垂直划分,存储到相应的数据表中。
另外,采用对象的全局标识(UID)的哈希值(Hash)进行水平划分,从而将对象数据划分到不同的数据节点(Datanode)的策略,需要面对数据迁移的问题,即当增加新的数据节点时,如何确保原有数据节点上的数据不进行或者尽量少进行迁移。
3.DDF的数据存储策略
DDF借鉴了HDFS的设计思想,在架构中引入了数据节点的概念,整个数据存储策略的设计理念如下。
(1)每个数据划分只可能存放在同一个数据库中,不允许一个数据划分分裂存放在多个数据库的情况出现。但是,具有相同数据对象类型的不同划分可以存放在不同的数据库中。
(2)允许不同类型的数据(如对象数据和查询数据)采用不同的划分策略。
Hadoop提供了一个基于HDFs的简单数据库HBase,它的设计思想和数据模型都与Google开发的模型简化的大规模分布式数据库BigTabIe极为相似。HBase不支持完全的关系数据模型,只为用户提供了简单的数据模型,让客户来动态控制数据的分布和格式。从数据模型角度看,HBase是一个稀疏的、长期存储的(存在硬盘上)、多维度的、排序的映射表。这张表的索引是行关键字、列关键字和时间戳。每个值是一个不解释的字符数组,用户需要自己解释存储的字串的类型和含义。这种模型具有很大的灵活性,通过仔细选择数据表示,用户可以控制数据的局部化。但是这种灵活性的代价就是不支持完全的关系数据模型,这导致传统的数据存储格式无法应用于HBase。Google自身的GFS是为网页搜索功能量身定做的,采用BigTable的简单数据模型可以以字符串形式灵活存储网页的URL、时间戳等信息。HDFS的设计完全借鉴了GFS的思想,因此从目前的版本来看,HDFS对网页搜索具有较好的支持,但是对于使用传统的关系数据模型的产品来说,HDFS并不是一个很好的选择,因为它不能提供传统的关系数据库的相关功能。如上所述,以Hadoop为例,目前的开源解决方案并不完全适用于某公司的新产品需求,因此我们需要参照现有解决方案,设计符合自身需要的新方案。
2.DDF的数据划分策略
面对大量的异构的用户数据,我们有必要对数据进行划分,以期得到更好的查询性能。
数据划分策略可分为垂直数据划分(Horizontal panition)和水平数据划分(VerticaI partition),在DDF中同时采用了这两种划分策略。垂直数据划分是按照功能划分:
(1)首先把对象数据、查询数据和其他数据划分到不同的数据表中(数据库的表)。
(2)对于对象数据,由于是按对象类型(Object type)访问的,那么我们可以进一步按照对象类型进行垂直划分,把不同类型的对象数据划分到相应的数据表中。
(3)对于查询数据,在目前的研究阶段,也将其按照对象类型进行垂直划分,存储到相应的数据表中。
另外,采用对象的全局标识(UID)的哈希值(Hash)进行水平划分,从而将对象数据划分到不同的数据节点(Datanode)的策略,需要面对数据迁移的问题,即当增加新的数据节点时,如何确保原有数据节点上的数据不进行或者尽量少进行迁移。
3.DDF的数据存储策略
DDF借鉴了HDFS的设计思想,在架构中引入了数据节点的概念,整个数据存储策略的设计理念如下。
(1)每个数据划分只可能存放在同一个数据库中,不允许一个数据划分分裂存放在多个数据库的情况出现。但是,具有相同数据对象类型的不同划分可以存放在不同的数据库中。
(2)允许不同类型的数据(如对象数据和查询数据)采用不同的划分策略。

责任编辑:何健
免责声明:本文仅代表作者个人观点,与本站无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
我要收藏
个赞
-

碳中和战略|赵英民副部长致辞全文
2020-10-19碳中和,碳排放,赵英民 -

两部门:推广不停电作业技术 减少停电时间和停电次数
2020-09-28获得电力,供电可靠性,供电企业 -
国家发改委、国家能源局:推广不停电作业技术 减少停电时间和停电次数
2020-09-28获得电力,供电可靠性,供电企业
-
碳中和战略|赵英民副部长致辞全文
2020-10-19碳中和,碳排放,赵英民 -

深度报告 | 基于分类监管与当量协同的碳市场框架设计方案
2020-07-21碳市场,碳排放,碳交易 -

碳市场让重庆能源转型与经济发展并进
2020-07-21碳市场,碳排放,重庆
-
两部门:推广不停电作业技术 减少停电时间和停电次数
2020-09-28获得电力,供电可靠性,供电企业 -
国家发改委、国家能源局:推广不停电作业技术 减少停电时间和停电次数
2020-09-28获得电力,供电可靠性,供电企业 -
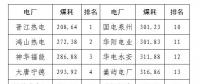
2020年二季度福建省统调燃煤电厂节能减排信息披露
2020-07-21火电环保,燃煤电厂,超低排放
-

四川“专线供电”身陷违法困境
2019-12-16专线供电 -
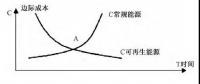
我国能源替代规范法律问题研究(上)
2019-10-31能源替代规范法律 -

区域链结构对于数据中心有什么影响?这个影响是好是坏呢!